
Biodiv Sci ›› 2026, Vol. 34 ›› Issue (1): 25398. DOI: 10.17520/biods.2025398 cstr: 32101.14.biods.2025398
• Special Feature: Methods for Ecological Data Analysis • Previous Articles Next Articles
Dingliang Xing*( )(
)( )
)
Received:2025-10-10
Accepted:2025-12-27
Online:2026-01-20
Published:2026-01-21
Contact:
Dingliang Xing
Supported by:Dingliang Xing. Influence of aggregation indices and estimation uncertainty on the aggregation-abundance relationship[J]. Biodiv Sci, 2026, 34(1): 25398.
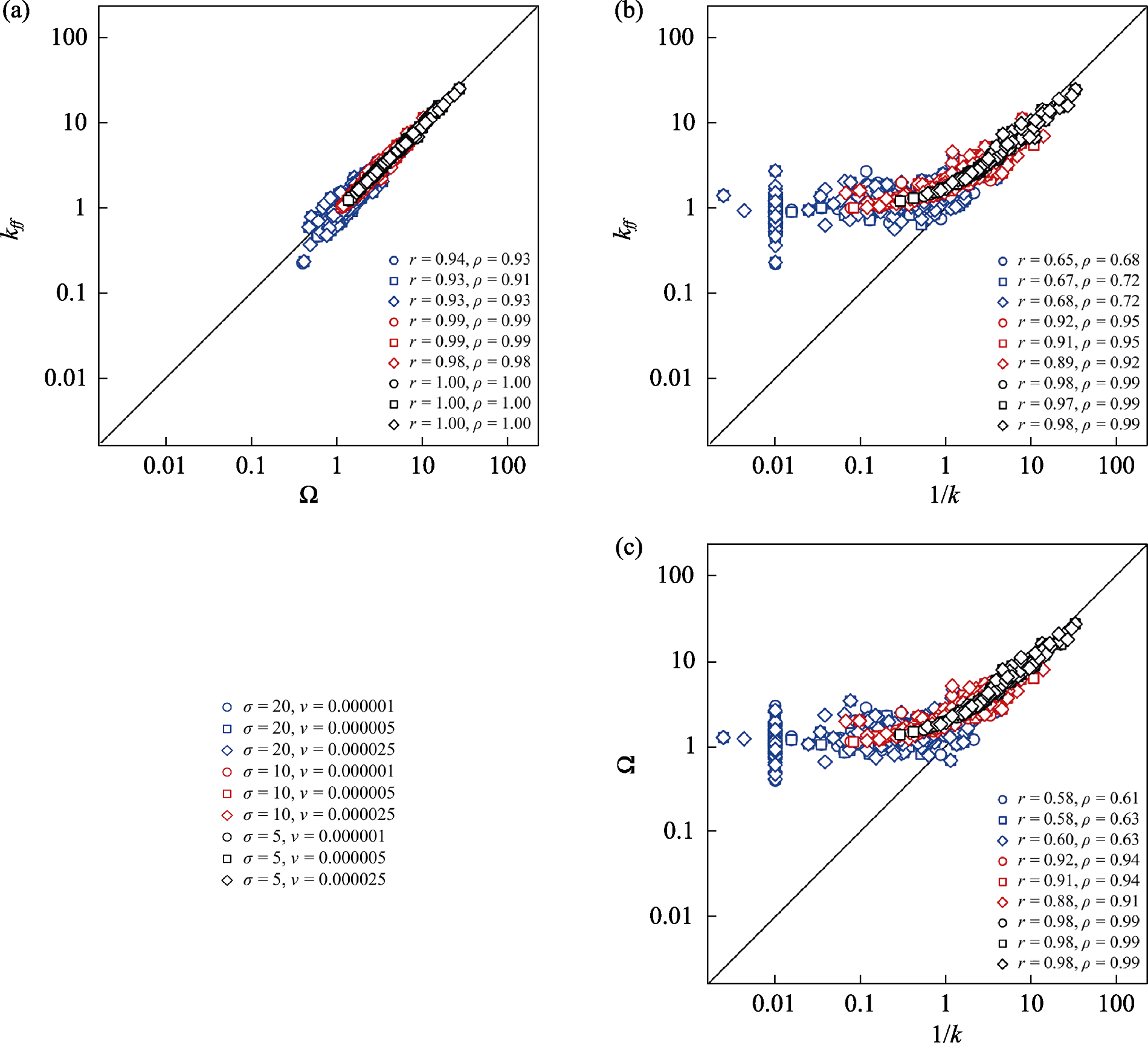
Fig. 1 Correlations among three indices of spatial aggregation. Different shapes and colors represent simulations from a spatially explicit neutral model with various combinations of parameters (dispersal potential, σ; and speciation rate, ν). The values r and ρ denote the Pearson and Spearman correlation coefficients, respectively. k, Aggregation parameter of the negative binomial distribution; Ω, Relative neighborhood density index of Condit et al. (2000); kff, Distance-weighted version of the relative neighborhood density index of Wiegand et al. (2025).
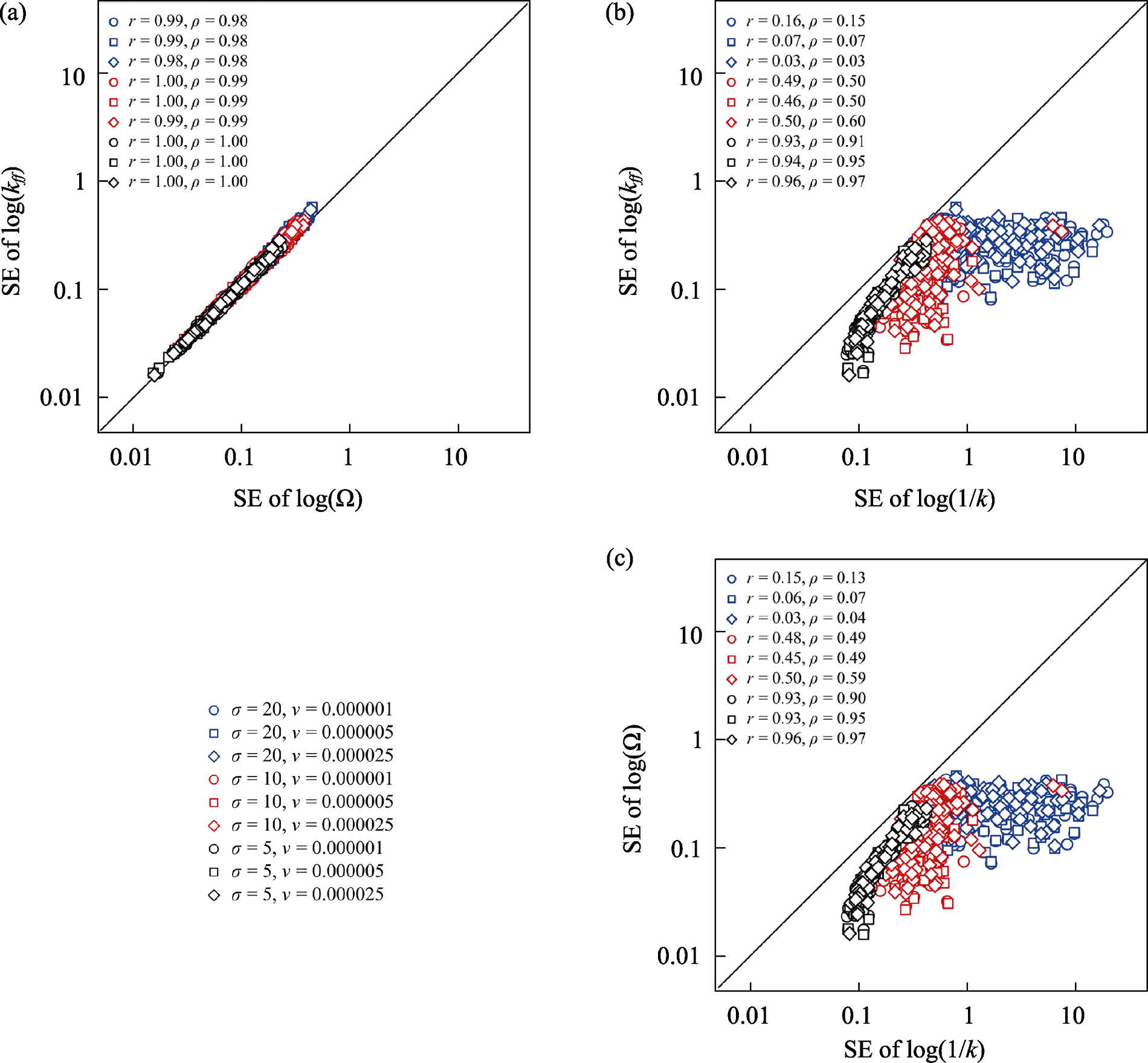
Fig. 2 Correlations among the standard errors (SE) of the three spatial aggregation indices. σ, ν, r, ρ, k, Ω, and kff are as described in Fig. 1.
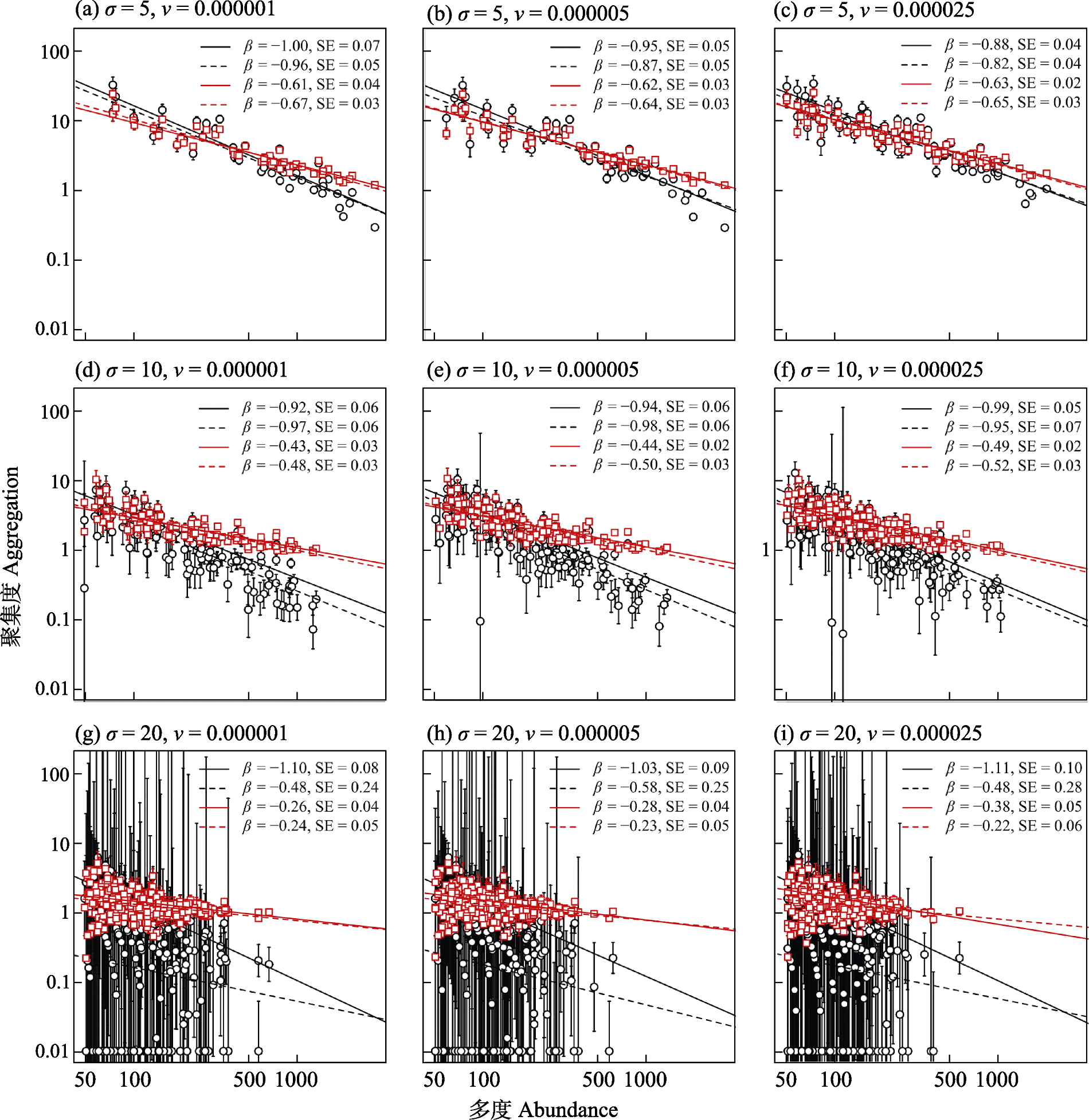
Fig. 3 Relationships between spatial aggregation and species abundance for simulated spatial-explicit neutral communities with different combinations of parameters (dispersal potential, σ; and speciation rate, ν). Aggregation is measured using either the negative binomial parameter k (where aggregation = 1/k; black circles) or the kff index (red squares). Solid and dashed lines represent weighted and non-weighted least-square regressions, respectively. β and SE denote the regression slope and its standard error.
| [1] |
Condit R, Ashton PS, Baker P, Bunyavejchewin S, Gunatilleke S, Gunatilleke N, Hubbell SP, Foster RB, Itoh A, LaFrankie JV, Lee HS, Losos E, Manokaran N, Sukumar R, Yamakura T (2000) Spatial patterns in the distribution of tropical tree species. Science, 288, 1414-1418.
DOI PMID |
| [2] | Deane DC, Xing DL, Hui C, McGeoch M, He FL (2022) A null model for quantifying the geometric effect of habitat subdivision on species diversity. Global Ecology and Biogeography, 32, 440-453. |
| [3] |
Du H, Hu F, Zeng FP, Wang KL, Peng WX, Zhang H, Zeng ZX, Zhang F, Song TQ (2017) Spatial distribution of tree species in evergreen-deciduous broadleaf karst forests in Southwest China. Scientific Reports, 7, 15664.
DOI PMID |
| [4] |
Gilbert GS, Howard E, Ayala-Orozco B, Bonilla-Moheno M, Cummings J, Langridge S, Parker IM, Pasari J, Schweizer D, Swope S (2010) Beyond the tropics: Forest structure in a temperate forest mapped plot. Journal of Vegetation Science, 21, 388-405.
DOI URL |
| [5] |
Green JL, Plotkin JB (2007) A statistical theory for sampling species abundances. Ecology Letters, 10, 1037-1045.
PMID |
| [6] |
Gu HY, Li JX, Qi G, Wang SZ (2020) Species spatial distributions in a warm-temperate deciduous broad-leaved forest in China. Journal of Forestry Research, 31, 1187-1194.
DOI |
| [7] |
Guo YL, Lu JM, Franklin SB, Wang QG, Xu YZ, Zhang KH, Bao DC, Qiao XJ, Huang HD, Lu ZJ, Jiang MX (2013) Spatial distribution of tree species in a species-rich subtropical mountain forest in Central China. Canadian Journal of Forest Research, 43, 826-835.
DOI URL |
| [8] |
Guyatt HL, Bundy DAP, Medley GF, Grenfell BT (1990) The relationship between the frequency distribution of Ascaris lumbricoides and the prevalence and intensity of infection in human communities. Parasitology, 101, 139-143.
DOI URL |
| [9] |
Hairston NG (1959) Species abundance and community organization. Ecology, 40, 404-416.
DOI URL |
| [10] | Harte J (2011) Maximum Entropy and Ecology: A Theory of Abundance, Distribution, and Energetics. Oxford University Press, Oxford. |
| [11] |
Hassell MP, Southwood TRE, Reader PM (1987) The dynamics of the viburnum whitefly (Aleurotrachelus jelinekii): A case study of population regulation. Journal of Animal Ecology, 56, 283-300.
DOI URL |
| [12] |
He FL, Gaston KJ (2003) Occupancy, spatial variance, and the abundance of species. The American Naturalist, 162, 366-375.
DOI URL |
| [13] | He FL, Legendre P (2002) Species diversity patterns derived from species-area models. Ecology, 83, 1185-1198. |
| [14] |
He FL, Legendre P, LaFrankie JV (1997) Distribution patterns of tree species in a Malaysian tropical rain forest. Journal of Vegetation Science, 8, 105-114.
DOI URL |
| [15] |
Hubbell SP (1979) Tree dispersion, abundance, and diversity in a tropical dry forest. Science, 203, 1299-1309.
PMID |
| [16] | Hubbell SP (2001) The Unified Neutral Theory of Biodiversity and Biogeography. Princeton University Press, Princeton. |
| [17] |
Hurlbert SH (1990) Spatial distribution of the montane unicorn. Oikos, 58, 257-271.
DOI URL |
| [18] | Kendall DG (1949) Stochastic processes and population growth. Journal of the Royal Statistical Society B: Methodological, 11, 230-282. |
| [19] |
Kitzes J, Brush M, Walters K (2021) A unified framework for species spatial patterns: Linking the occupancy area curve, Taylor’s Law, the neighborhood density function and two-plot species turnover. Ecology Letters, 24, 2043-2053.
DOI URL |
| [20] | Krebs CJ (1989) Ecological Methodology. Harper & Row, New York. |
| [21] |
Kretzschmar M, Adler FR (1993) Aggregated distributions in models for patchy populations. Theoretical Population Biology, 43, 1-30.
PMID |
| [22] |
Li L, Huang ZL, Ye WH, Cao HL, Wei SG, Wang ZG, Lian JY, Sun IF, Ma KP, He FL (2009) Spatial distributions of tree species in a subtropical forest of China. Oikos, 118, 495-502.
DOI URL |
| [23] |
Lowe WH, McPeek MA (2014) Is dispersal neutral? Trends in Ecology & Evolution, 29, 444-450.
DOI URL |
| [24] |
McGill BJ (2010) Towards a unification of unified theories of biodiversity. Ecology Letters, 13, 627-642.
DOI PMID |
| [25] | Niu CJ, Lou AR, Sun RY, Li QF (2023) Basic Ecology, 4th edn. Higher Education Press, Beijing. (in Chinese) |
| [牛翠娟, 娄安如, 孙儒泳, 李庆芬 (2023) 基础生态学(第四版). 高等教育出版社, 北京.] | |
| [26] |
Plotkin JB, Muller-Landau HC (2002) Sampling the species composition of a landscape. Ecology, 83, 3344-3356.
DOI URL |
| [27] |
Song HJ, Xu YD, Hao J, Zhao BQ, Guo DG, Shao HB (2017) Investigating distribution pattern of species in a warm-temperate conifer-broadleaved-mixed forest in China for sustainably utilizing forest and soils. Science of the Total Environment, 578, 81-89.
DOI URL |
| [28] | Taylor RAJ (2019) Taylor’s Power Law: Order and Pattern in Nature. Elsevier, San Diego. |
| [29] |
Thompson SED, Chisholm RA, Rosindell J (2020) Pycoalescence and rcoalescence: Packages for simulating spatially explicit neutral models of biodiversity. Methods in Ecology and Evolution, 11, 1237-1246.
DOI |
| [30] |
Wang XG, Ye J, Li BH, Zhang J, Lin F, Hao ZQ (2010) Spatial distributions of species in an old-growth temperate forest, northeastern China. Canadian Journal of Forest Research, 40, 1011-1019.
DOI URL |
| [31] |
Wiegand T, Uriarte M, Kraft NJB, Shen GC, Wang XG, He FL (2017) Spatially explicit metrics of species diversity, functional diversity, and phylogenetic diversity: Insights into plant community assembly processes. Annual Review of Ecology, Evolution, and Systematics, 48, 329-351.
DOI URL |
| [32] | Wiegand T, Wang XG, Anderson-Teixeira KJ, Bourg NA, Cao M, Ci XQ, Davies SJ, Hao ZQ, Howe RW, Kress WJ, Lian JY, Li J, Lin LX, Lin Y, Ma KP, McShea W, Mi XC, Su SH, Sun IF, Wolf A, Ye WH, Huth A (2021) Consequences of spatial patterns for coexistence in species-rich plant communities. Nature Ecology & Evolution, 5, 965-973. |
| [33] |
Wiegand T, Wang XG, Fischer SM, Kraft NJB, Bourg NA, Brockelman WY, Cao GH, Cao M, Chanthorn W, Chu CJ, Davies S, Ediriweera S, Savitri Gunatilleke CV, Gunatilleke IAUN, Hao ZQ, Howe R, Jiang MX, Jin GZ, Kress WJ, Li BH, Lian JY, Lin LX, Liu F, Ma KP, McShea W, Mi XC, Myers JA, Nathalang A, Orwig DA, Shen GC, Su SH, Sun IF, Wang XH, Wolf A, Yan ER, Ye WH, Zhu Y, Huth A (2025) Latitudinal scaling of aggregation with abundance and coexistence in forests. Nature, 640, 967-973.
DOI |
| [34] |
Wilber MQ, Kitzes J, Harte J (2015) Scale collapse and the emergence of the power law species-area relationship. Global Ecology and Biogeography, 24, 883-895.
DOI URL |
| [35] |
Xing DL, He FL (2021) Analytical models for β-diversity and the power-law scaling of β-deviation. Methods in Ecology and Evolution, 12, 405-414.
DOI URL |
| [36] | Zhang J, Hao ZQ, Song B, Ye J, Li BH, Yao XL (2007) Spatial distribution patterns and associations of Pinus koraiensis and Tilia amurensis in broad-leaved Korean pine mixed forest in Changbai Mountain. Chinese Journal of Applied Ecology, 18, 1681-1687. (in Chinese with English abstract) |
| [张健, 郝占庆, 宋波, 叶吉, 李步杭, 姚晓琳 (2007) 长白山阔叶红松林中红松与紫椴的空间分布格局及其关联性. 应用生态学报, 18, 1681-1687.] | |
| [37] |
Zhang Z, Hu G, Zhu J, Ni J (2013) Aggregated spatial distributions of species in a subtropical karst forest, southwestern China. Journal of Plant Ecology, 6, 131-140.
DOI |
| [1] | Yingni Wang, Jingjing Lei, Yuxin Bao, Dan Liao, Xinna Zhang, Juan Wang. Divergent of sexual systems in impacting the spatial distribution patterns of dominant tree species within natural coniferous-broadleaf mixed forests in Northeast China [J]. Biodiv Sci, 2025, 33(11): 25101-. |
| [2] | Minghui Wang, Zhaoquan Chen, Shuaifeng Li, Xiaobo Huang, Xuedong Lang, Zihan Hu, Ruiguang Shang, Wande Liu. Spatial pattern of dominant species with different seed dispersal modes in a monsoon evergreen broad-leaved forest in Pu’er, Yunnan Province [J]. Biodiv Sci, 2023, 31(9): 23147-. |
| [3] | Shidong Li. On the spatiotemporal development and driving factors of national parks in China and the United States [J]. Biodiv Sci, 2023, 31(6): 23040-. |
| [4] | Hong Chen, Xiaoqing Xian, Yixue Chen, Na Lin, Miaomiao Wang, Zhipeng Li, Jian Zhao. Spatial pattern and driving factors on the prevalence of red imported fire ant (Solenopsis invicta) in island cities: A case study of Haitan Island, Fujian [J]. Biodiv Sci, 2023, 31(5): 22501-. |
| [5] | Wei Zhang, Dongdong Zhai, Fei Xiong, Hongyan Liu, Yuanyuan Chen, Ying Wang, Chuansong Liao, Xinbin Duan, Huiwu Tian, Huatang Deng, Daqing Chen. Community structure and functional diversity of fishes in the Three Gorges Reservoir [J]. Biodiv Sci, 2023, 31(2): 22136-. |
| [6] | Xi Tian, Wencong Liu, Jiesheng Rao, Xiaofeng Wang, Tao Yang, Xi Chen, Qiuyu Zhang, Qiming Liu, Yanxiao Xu, Xu Zhang, Zehao Shen. Patterns and causes of forest gap disturbance in a semi-humid evergreen broadleaved forest in the Jizu Mountains, Yunnan [J]. Biodiv Sci, 2023, 31(11): 23219-. |
| [7] | Nan Ye, Beibei Hou, Chao Wang, Ruiwu Wang, Jianxiao Song. Spatial self-organization in microbial interactions [J]. Biodiv Sci, 2022, 30(5): 21458-. |
| [8] | Fei Fu, Huiyu Wei, Yuteng Chang, Beixin Wang, Kai Chen. Elevational patterns of life history and ecological trait diversity of aquatic insects in the middle of the Lancang River: The effects of climate and land use variables [J]. Biodiv Sci, 2022, 30(5): 21332-. |
| [9] | Mengzhen Lu, Fuping Zeng, Tongqing Song, Wanxia Peng, Hao Zhang, Liang Su, Kunping Liu, Weining Tan, Hu Du. Spatial distribution pattern and habitat-association of snags in karst evergreen deciduous broad-leaved mixed forests [J]. Biodiv Sci, 2022, 30(4): 21340-. |
| [10] | Jiahuan Sun, Dong Liu, Jiaqi Zhu, Shuning Zhang, Meixiang Gao. Spatial distribution pattern of soil mite community and body size in wheat- maize rotation farmland [J]. Biodiv Sci, 2022, 30(12): 22292-. |
| [11] | Xiao Huang,Jiang Zhu,Lan Yao,Xunru Ai,Jin Wang,Manling Wu,Qiang Zhu,Shaolin Chen. Structure and spatial distribution pattern of a native Metasequoia glyptostroboides population in Hubei [J]. Biodiv Sci, 2020, 28(4): 463-473. |
| [12] | Yaobin Song, Li Xu, Junpeng Duan, Weijun Zhang, Xiaolu Shentu, Tianxiang Li, Runguo Zang, Ming Dong. Sex ratio and spatial pattern of Taxus fuana, a Wild Plant with Extremely Small Populations in Tibet [J]. Biodiv Sci, 2020, 28(3): 269-276. |
| [13] | Xinting Wang, Jing Chai, Chao Jiang, Yang Tai, Yanyan Chi, Weihua Zhang, Fang Liu, Suying Li. Population spatial pattern of Stipa grandis and its response to long-term overgrazing [J]. Biodiv Sci, 2020, 28(2): 128-134. |
| [14] | Zhenpeng Ge, Quanxing Liu. More than the sum of its parts: Self-organized patterns and emergent properties of ecosystems [J]. Biodiv Sci, 2020, 28(11): 1431-1443. |
| [15] | Li Qiang, Wang Bin, Deng Yun, Lin Luxiang, Dawa Zhaxi, Zhang Zhiming. Correlation between spatial distribution of forest canopy gaps and plant diversity indices in Xishuangbanna tropical forests [J]. Biodiv Sci, 2019, 27(3): 273-285. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Copyright © 2026 Biodiversity Science
Editorial Office of Biodiversity Science, 20 Nanxincun, Xiangshan, Beijing 100093, China
Tel: 010-62836137, 62836665 E-mail: biodiversity@ibcas.ac.cn