
Biodiv Sci ›› 2015, Vol. 23 ›› Issue (4): 550-555. DOI: 10.17520/biods.2015120 cstr: 32101.14.biods.2015120
• Software introduction • Previous Articles
Xiaoting Xu1, Zhiheng Wang1,*( ), Dimitar Dimitrov2, Carsten Rahbek3,4
), Dimitar Dimitrov2, Carsten Rahbek3,4
Received:2015-05-07
Accepted:2015-07-09
Online:2015-07-20
Published:2015-08-03
Contact:
Wang Zhiheng
Xiaoting Xu, Zhiheng Wang, Dimitar Dimitrov, Carsten Rahbek. Using NCBIminer to search and download nucleotide sequences from GenBank[J]. Biodiv Sci, 2015, 23(4): 550-555.
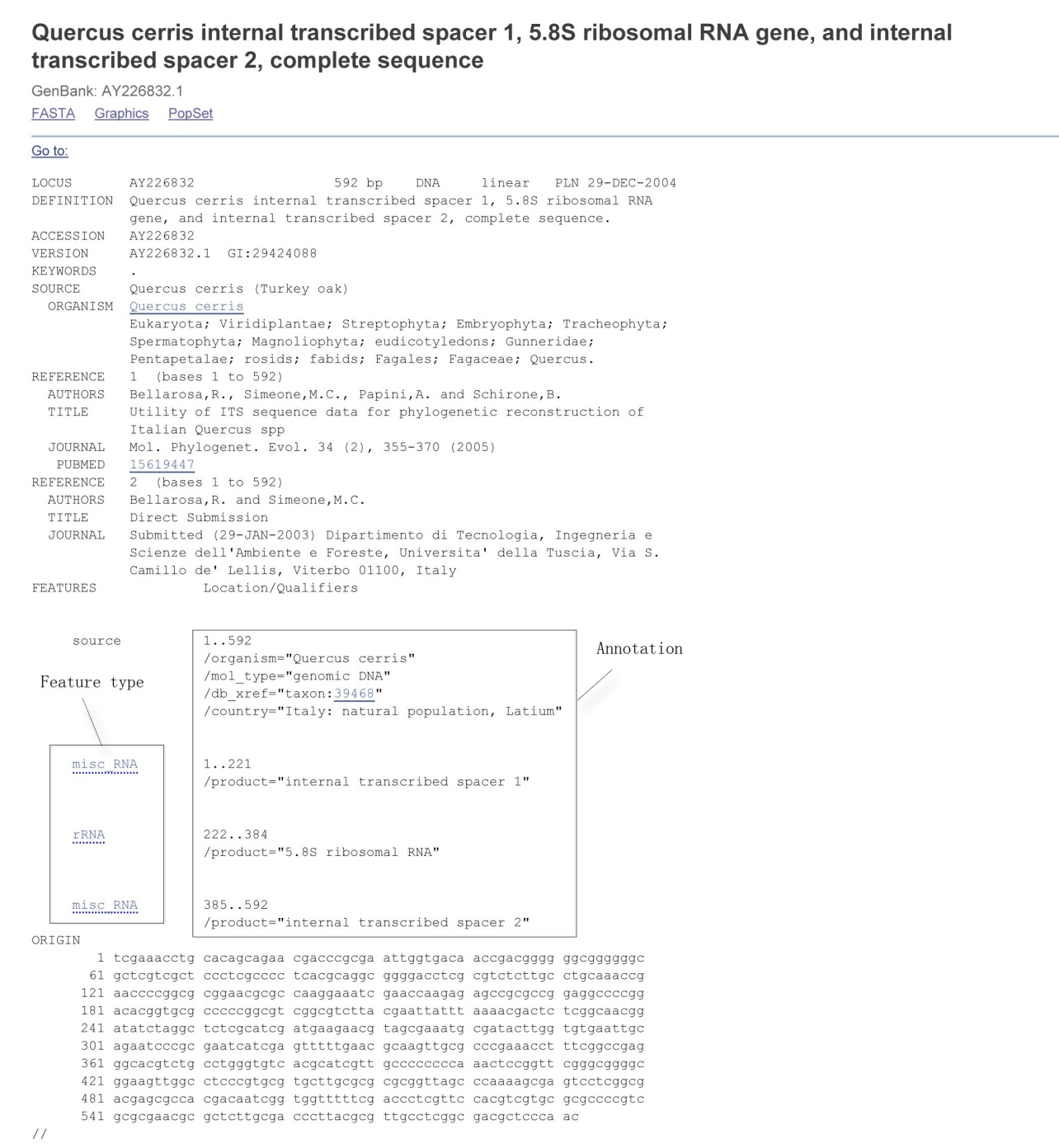
Appendix 1 Data format for a sequence in GenBank. The items in the left box are feature types defined in GenBank, while those in the right box are GenBank annotation information.
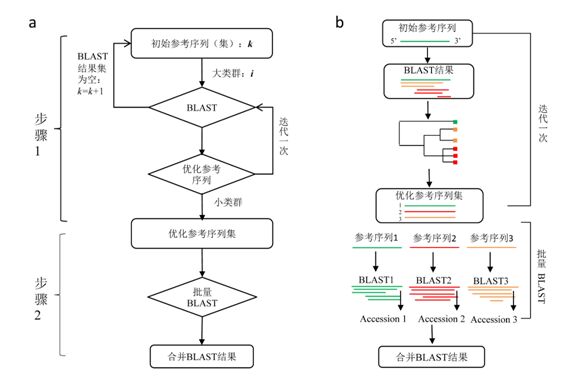
Appendix 2 Data format for a sequence in GenBank. The items in the left box are feature types defined in GenBank, while those in the right box are GenBank annotation informatioppendix 2 NCBIminer workflow. a, Major steps of the NCBIminer’s work flow; b, The algorithms for the establishment of improved reference sequences and sequence combination of multiple queries. Modified from Xu et al. (2015).
| 1 | Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool.Journal of Molecular Biology, 215, 403-410. |
| 2 | Chen ZD (陈之端), Li DZ (李德铢) (2013) On Barcode of Life and Tree of Life.Plant Diversity and Resources(植物分类与资源学报), 35, 675-681. (in Chinese with English abstract) |
| 3 | Driskell AC, Ané C, Burleigh JG, McMahon MM, O’Meara BC, Sanderson MJ (2004) Prospects for building the Tree of Life from large sequence databases.Science, 306, 1172-1174. |
| 4 | Holt B, Lessard JP, Borregaard MK, Fritz SA, Araujo MB, Dimitrov D, Fabre PH, Graham CH, Graves GR, Jonsson KA, Nogues-Bravo D, Wang ZH, Whittaker RJ, Fjeldsa J, Rahbek C (2013) An update of Wallace’s zoogeographic regions of the world.Science, 339, 74-78. |
| 5 | Jones M, Koutsovoulos G, Blaxter M (2011) iPhy: an integrated phylogenetic workbench for supermatrix analyses.BMC Bioinformatics, 12, 30. |
| 6 | Li DC (2013) Similarity analysis of DNA sequences based on CLZ complexity.Journal of Computational and Theoretical Nanoscience, 10, 481-487. |
| 7 | Li DZ, Gao LM, Li HT, Wang H, Ge XJ, Liu JQ, Chen ZD, Zhou SL, Chen SL, Yang JB, Fu CX, Zeng CX, Yan HF, Zhu YJ, Sun YS, Chen SY, Zhao L, Wang K, Yang T, Duan GW, Grp CPB (2011) Comparative analysis of a large dataset indicates that internal transcribed spacer (ITS) should be incorporated into the core barcode for seed plants. Proceedings of the National Academy of Sciences, USA, 108, 19641-19646. |
| 8 | Lu LM (鲁丽敏), Sun M (孙苗), Zhang JB (张景博), Li HL (李洪雷), Lin L (林立), Yang T (杨拓), Chen M (陈闽), Chen ZD (陈之端) (2014) Tree of Life and its applications.Biodiversity Science(生物多样性), 22, 3-20. (in Chinese with English abstract) |
| 9 | Pearse WD, Purvis A (2013) phyloGenerator: an automated phylogeny generation tool for ecologists.Methods in Ecology and Evolution, 4, 692-698. |
| 10 | Pei NC (裴男才) (2015) Applications of DNA barcoding in evolutionary ecology.Biodiversity Science(生物多样性), 23, 291-292. (in Chinese) |
| 11 | Qiu Q, Zhang GJ, Ma T, Qian WB, Wang JY, Ye ZQ, Cao CC, Hu QJ, Kim J, Larkin DM, Auvil L, Capitanu B, Ma J, Lewin HA, Qian XJ, Lang YS, Zhou R, Wang LZ, Wang K, Xia JQ, Liao SG, Pan SK, Lu X, Hou HL, Wang Y, Zang XT, Yin Y, Ma H, Zhang J, Wang ZF, Zhang YM, Zhang DW, Yonezawa T, Hasegawa M, Zhong Y, Liu WB, Zhang Y, Huang ZY, Zhang SX, Long RJ, Yang HM, Wang J, Lenstra JA, Cooper DN, Wu Y, Wang J, Shi P, Wang J, Liu JQ (2012) The yak genome and adaptation to life at high altitude.Nature Genetics, 44, 946-949. |
| 12 | Ren BQ (任保青), Chen ZD (陈之端) (2010) DNA barcoding plant life.Chinese Bulletin of Botany(植物学报), 45, 1-12. (in Chinese with English abstract) |
| 13 | Sanderson M, Boss D, Chen D, Cranston K, Wehe A (2008) The PhyLoTA browser: processing GenBank for molecular phylogenetics research.Systematic Biology, 57, 335-346. |
| 14 | Xu X, Wang Z, Rahbek C, Lessard J-P, Fang J (2013) |
| 15 | Evolutionary history influences the effects of water-energy dynamics on oak diversity in Asia.Journal of Biogeography, 40, 2146-2155. |
| 16 | Xu XT, Dimitrov D, Rahbek C, Wang ZH (2015) NCBIminer: sequences harvest from Genbank.Ecography, 38, 426-430. |
| 17 | Yang ZY, Ran JH, Wang XQ (2012) Three genome-based phylogeny of Cupressaceae s.l.: further evidence for the evolution of gymnosperms and southern hemisphere biogeography.Molecular Phylogenetics and Evolution, 64, 452-470. |
| 18 | Zanne AE, Tank DC, Cornwell WK, Eastman JM, Smith SA, FitzJohn RG, McGlinn DJ, O’Meara BC, Moles AT, Reich PB, Royer DL, Soltis DE, Stevens PF, Westoby M, Wright IJ, Aarssen L, Bertin RI, Calaminus A, Govaerts R, Hemmings F, Leishman MR, Oleksyn J, Soltis PS, Swenson NG, Warman L, Beaulieu JM (2013) Three keys to the radiation of angiosperms into freezing environments.Nature, 506, 89-92. |
| [1] | Xiaoxu Jia, Wanqiang Chen, Xiujun Tang, Yanfeng Fan, Jing Zhang, Haiwei Wang, Yushi Gao. Genetic diversity and gene introgression of mitochondrial DNA control region in indigenous chickens from Southwest China [J]. Biodiv Sci, 2026, 34(5): 26003-. |
| [2] | Cuiyi Jiang, Zhijing Xie, Zhongping Tian, Yueying Li, Mingxin Zheng, Shuai Fang, Mierkamili Maimaiti, Erfan Akberjan, Meixiang Gao, Jian Zhang. The role of microtopography in shaping forest soil Collembola community assembly in western Tianshan Mountains of Xinjiang [J]. Biodiv Sci, 2026, 34(4): 25300-. |
| [3] | Jinyue Zhang, Baole Bian, Tairan Tang, Wenhao Nong, Shufeng Zhu, Xinmin Lu. Plant-rhizosphere microbe interaction and its response to herbivory: A review [J]. Biodiv Sci, 2026, 34(4): 25334-. |
| [4] | Luhong Wang, Bo Li, Panyan Yang, Jiaqin Huang, Yuting Xie, Xin Du, Yi Wen, Bin Wang. Effects of ecological factors on the multidimensional diversity of breeding birds communities in Sichuan Province [J]. Biodiv Sci, 2026, 34(4): 25464-. |
| [5] | Xiao-Yong Chen. On the effective ex situ conservation of rare or endangered plants: Definition, standards and recommendations [J]. Biodiv Sci, 2026, 34(4): 25448-. |
| [6] | Boyao Li, Tiancheng Sheng, Xiaoyun Xing. Impact of biodiversity risk on corporate financial performance: Evidence from listed companies in China [J]. Biodiv Sci, 2026, 34(4): 25330-. |
| [7] | Dexi Zhang, Qian Zhou, Xuezhu Pei, Hongyong Zhang, Yingtai Pei, Shan Sun, Mingxin Liu, Lixun Zhang, Changming Zhao. Dataset of arthropod specimen images and DNA barcodes in forest ecosystem of the Xinglong Mountains of Gansu Province [J]. Biodiv Sci, 2026, 34(4): 25409-. |
| [8] | Pengfei Fan. Research advances and conservation of gibbons in China [J]. Biodiv Sci, 2026, 34(3): 25456-. |
| [9] | Dongpo Xia, Jing Li, Jundong Tian, Zhonghao Huang, Chengfeng Wu, Shiwang Chen, Jinhua Li. Research progress of wild Macaca species in China [J]. Biodiv Sci, 2026, 34(3): 25460-. |
| [10] | Songtao Guo, Guoliang Chen, Baoguo Li. Advances in primatology in China [J]. Biodiv Sci, 2026, 34(3): 25462-. |
| [11] | Zhicheng Kang, Chunlei Gao, Jianing Guo, Fanping Meng, Zongling Wang. Diversity, distribution and environmental correlation of harmful dinoflagellate cysts in the Bohai Sea and the North Yellow Sea in spring [J]. Biodiv Sci, 2026, 34(3): 25426-. |
| [12] | Jun Liu, Tianxiang Zhang, Yixuan Zhang, Xiaofeng Huang, Weijie Han, Wenguo Wu, Xiaofei Huang, Lizheng Huang, Yang Zhang. Diet and nutritional strategies of sika deer in Taohongling, Jiangxi, based on DNA metabarcoding [J]. Biodiv Sci, 2026, 34(2): 25214-. |
| [13] | Wenmin Zeng, Xia Yang, Chengyu Zou, Yanxin Li, Xiannan Wang, Yiting Wei, Yanqin Xu, Yin Zhou. Advances in formation mechanisms and taxonomy of plant species complex [J]. Biodiv Sci, 2026, 34(2): 25321-. |
| [14] | Ziling Yan, Xiaoyu Chen, Meng Yao. A comparative evaluation of bioinformatic pipelines for invertebrate biodiversity profiling via environmental DNA metabarcoding [J]. Biodiv Sci, 2026, 34(1): 25369-. |
| [15] | Shuang Zhang, Bo Song. Several key questions when conducting a meta-analysis [J]. Biodiv Sci, 2026, 34(1): 25308-. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Copyright © 2026 Biodiversity Science
Editorial Office of Biodiversity Science, 20 Nanxincun, Xiangshan, Beijing 100093, China
Tel: 010-62836137, 62836665 E-mail: biodiversity@ibcas.ac.cn