|
|
|||||||||||||||||||||
|
联合物种分布模型与生物群落层次建模框架: 生态学理论、方法及应用
生物多样性
2026, 34 (1):
25364-.
DOI: 10.17520/biods.2025364
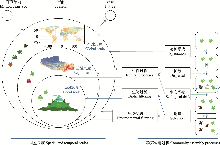
理解环境过滤、生物相互作用与中性过程如何共同塑造物种分布与群落结构, 是现代群落生态学的核心问题。然而, 传统多样性指数、排序分析及单物种分布模型(single-species distribution models, SDMs)难以同时整合物种间关联、环境梯度、性状与谱系等多维信息, 导致对群落构建机制的解析能力受限。联合物种分布模型(joint species distribution models, JSDMs)特别是生物群落层次建模(hierarchical modelling of species communities, HMSC)框架的提出, 为群落尺度的机制推断提供了统一而灵活的贝叶斯工具。本文系统综述了HMSC的统计结构、数学原理与推断机制, 构建了一个从数据组织、模型设定、马尔可夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC)估计、模型评估到生态解释与预测的完整分析流程。同时结合苔藓群落数据配套编写了《联合物种分布模型HMSC的应用分步教程》, 通过分步讲解与可运行R代码, 助力研究者快速掌握该方法的实操应用。在理论部分, 本文明确了HMSC如何在统一的贝叶斯层级框架下整合环境梯度、物种性状、系统发育关系以及空间结构, 从而分离环境过滤、生物过滤与扩散限制的统计信号。在方法层面, 本文通过解析潜变量模型的数学结构, 阐明了残差相关在生态解释中的边界, 为理解物种共现信号、区分环境效应与未观测因子提供了理论依据; 对比了HMSC与其他主流JSDMs工具及传统群落统计方法的优势及适用性。在应用层面, 综述了其在森林、湿地、草原、海洋、城市及微生物生态学中的应用进展, 展示了其在保护规划、入侵种风险评估、共现网络分析及情景预测中的广泛价值; 随着图形处理器加速与迁移学习与大规模高维数据框架的发展, HMSC可提升稀有物种生态位估计与分布预测, 使数十万物种的群落建模成为可能。综上, JSDMs及HMSC不仅在生态统计方法论上实现了从单物种预测到多物种‒多维信息整合的跨越, 更为生态理论检验、群落构建机制解析及保护决策制定提供了高效、可扩展且能量化不确定性的工具平台。
表2
生物群落层次建模框架核心模型的数据矩阵及其维度
正文中引用本图/表的段落
在数据层面, HMSC的输入包括群落数据Y、环境变量X、性状数据T、系统发育矩阵C、研究设计Π以及空间坐标S。其中, 各索引及其范围列于表1, 主要数据矩阵及其维度列于表2。该模型可适配多种响应变量类型(如存在-缺失、计数、连续变量), 并支持多层级研究设计, 适合分析多物种、多尺度、多来源的生态数据。例如, 在模型实现上, 存在-缺失型数据通常采用二项分布或probit链接, 而多度型数据可建模为泊松或负二项分布, 以匹配计数/生物量等指标的离散性与过度离散特征。
在HMSC框架下, 所有与群落相关的信息最终都需要整理为若干结构化的矩阵, 以便在统一的层次模型中联合分析。就模型实现而言, 可以将输入数据大体分为“样点层信息”和“物种层信息”两类(表2)。样点层的核心是群落矩阵, 其行对应采样单元、列对应物种, 用于记录每个样点上各物种的出现与否或多度水平, 例如苔藓物种在不同样方中的盖度、生物量或个体数(Bohmann et al., 2014; Korhonen et al., 2024)。与群落矩阵Y同步的是环境矩阵X, 它同样以采样单元为行, 以环境协变量为列, 刻画每个样点的环境背景, 如温度、降水、土壤pH、基质类型等(Fick & Hijmans, 2017)。研究设计相关的信息则通过Π和S两个对象编码: Π用分层ID表示样点在时间与空间上的嵌套结构(例如样点隶属的样带、样地或年份), S则存储这些层级单元在地理空间或时间轴上的具体位置(如经纬度或调查日期), 为构建空间/时间相关的随机效应提供基础(Tikhonov et al., 2020)。
物种层信息主要包括性状矩阵T和系统发育矩阵C (表2)。T以物种为行、性状为列, 汇集了物种在形态、生理或功能上的关键特征, 例如苔藓的持水能力、茎高、孢子大小等, 数据库如全球植物性状数据库(
在数据准备阶段, 需要确保这几类数据在索引体系上严格对齐: Y的物种顺序必须与T和C中的物种顺序完全一致, Y的样点顺序则应与X中的样点顺序以及Π中的层级编号一一对应(表2)。只有在物种命名和样点编码保持完全一致的前提下, 模型才能正确地把群落记录、环境背景、物种性状、谱系信息以及时空结构关联起来, 从而实现多源数据在同一层级框架下的联合建模。
第四阶段是参数估计与生态学解读。在模型收敛与性能确认之后, 需要对参数进行生态学意义上的解读。核心内容包括: 物种生态位特征及其对性状和系统发育的依赖性、物种间残差关联结构。这些信息可用于识别环境过滤、生物相互作用、扩散限制、缺失协变量与生态漂变等潜在过程。解读过程中必须结合生态理论与领域知识, 避免过度推断或误读(相关参数设置见附录1-表S2)。
本文的其它图/表
|
备案号:京ICP备16067583号-7
Copyright © 2026 版权所有 《生物多样性》编辑部
地址: 北京香山南辛村20号, 邮编:100093
电话: 010-62836137, 62836665 E-mail: biodiversity@ibcas.ac.cn
![]()