|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
中国生物多样性在线数据处理平台的构建
生物多样性
2022, 30 (11):
22356-.
DOI: 10.17520/biods.2022356
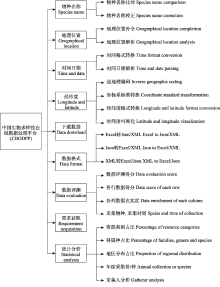
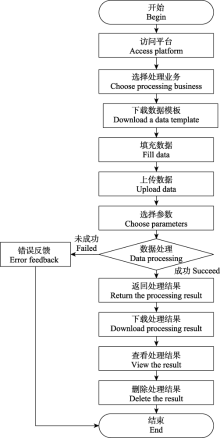
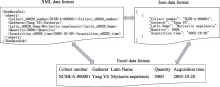
高质量的生物多样性数据能够为生物多样性的研究与保护提供数据支撑。目前研究人员开发了大量的生物多样性数据处理软件或工具, 包括工作流系统、R语言包、Python语言包和Excel工具等, 但是使用这些软件或工具需要用户安装相应的软件客户端, 并掌握一定的编程语言、软件开发和复杂的Excel公式等知识和技能。为降低用户的学习成本和使用门槛, 本文采用了Browser/Server模式设计技术、Web技术、可视化技术、响应式开发技术、网络爬虫技术、数据处理技术和Solr智能检索技术等, 针对不同维度的生物多样性数据设计和开发了相应的数据处理模块, 构建了中国生物多样性在线数据处理平台(
表1
测试示例在不同的容错级别下的处理结果
正文中引用本图/表的段落
物种名称处理模块以《中国生物物种名录》(中国科学院生物多样性委员会, 2022)为基础数据加工成数据处理平台的数据字典, 并基于Solr高效智能检索技术实现。实现步骤主要包括: (1)为了提升物种名称的处理效率, 将《中国生物物种名录》中以“parent_id”等外键的低冗余结构化数据, 处理成无外键的高冗余结构化数据, 从而减少数据的关联查询; (2)为了提高物种名称比对的命中率, 将《中国生物物种名录》中的物种接受名、异名、拉丁学名和中文名均作为物种名称比对的本底数据, 同时需要将拉丁名中常见的符号(如空格、逗号和点号等)处理成标准的格式从而形成数据字典; (3)为数据字典建立索引; (4)编程开发实现物种名称处理模块。该模块可实现对生物的界、门、纲、目、科、属、种和变种等级别的接受名、异名、拉丁名和中文名等物种名称进行处理, 不仅提供了物种名称的数据比对功能, 还提供了物种名称的数据校正功能, 且支持用户选择物种名称比对和校正时的数据容错级别, 以物种名称Sinularia muralis为例, 各种测试示例在不同的容错级别下处理结果如表1所示。
收集、整理和分析高质量的生物多样性数据是认知和回答物种分类、分布、起源与进化、时空动态等科学问题的基础, 并支撑实现生物多样性研究和保护设定的短期和长期目标(张健等, 2017, 2021)。数据质量评测模块可以对生物多样性数据各行的完整性和各列的充实度进行评测, 如某个数据集共有10列, 其中某行数据在其中8列均有内容, 则说明该行数据比较完整, 该行数据的完整性较高; 又假设这个数据集有一列代表“采集时间”, 该数据集共有1,000行, 其中仅有10行数据的“采集时间”列有数据或有规范的采集时间数据, 则说明这个数据集的“采集时间”列的数据比较缺乏, 该列充实度较低。用户可根据需求选择默认加权方案(各列权重默认相同)或为各列自定义加权系数, 同时也可以根据需求选择是否对科、属、种和时间列的数据进行校验比对和过滤, 数据评测完成后平台向用户反馈详细的评测报告和统计分析结果, 如图6所示, 用户可根据评测报告和统计分析结果判断该数据的质量情况。
本文的其它图/表
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||