



目前全球自然界中已知的鸟类超过一万种, 鸟类对生态系统的稳定至关重要(杨俊锋等, 2022)。鸟类位于食物链的上层, 从它们的生存状态可以了解生物圈中的变化, 因此, 鸟类是栖息地质量和环境污染的绝佳指标(Dagan & Izhaki, 2019)。鸟类体型较小, 活动灵敏, 但鸣叫声清晰响亮, 区分度高, 因此选择鸟鸣声进行研究的难度较之图像大大减小。通过适当的声音监测和分类, 可以通过鸟群状态变化感知某一地区生活质量的变化。除了作为环境污染的评价指标外, 鸟声识别在现实中的应用也十分广泛, 因为鸟鸣声包含丰富的生态学信息, 这些信息可以运用到动物行为分析、监护、生态环境的恢复等方面(Incze et al, 2018)。研究鸟声识别技术能够实现长时间无人值守监测, 减轻了生态保护人员的工作, 同时极大节约了成本。收集到的鸟声数据可供我们进行生态监测, 以了解鸟类的分布状态, 分析鸟群迁徙动向。同时, 研究鸟声识别技术对鸟害预防也意义重大。我国对输电线路鸟害防护方面的研究已经持续了多年, 随着人工智能的兴起, 鸟害预防的研究思路从物理被动防护转向了与人工智能技术结合的主动驱赶(Mahendra et al, 2021)。研究人员将输电线路驱鸟器与人工智能技术相结合, 通过鸟鸣声识别技术, 在对输电线路鸟类进行有效监测后启动电子驱鸟器(宋福春等, 2021)。综上, 对鸟鸣声的识别技术进行研究具有重要意义(吕坤朋等, 2021)。
本文基于Xeno-Canto世界野生鸟类声音公开数据集(
1 方法
图1
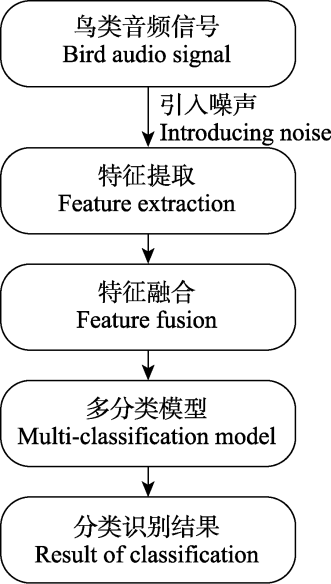
1.1 数据预处理
若直接对采集到的声信号数据提取特征并分类识别, 信号所带有的环境因素会对特征产生影响, 不能达到期望的效果, 所以需要对数据进行预处理,使样本数据中的信息更为明显, 减少对特征提取的影响。根据对数据的分析以及对本领域的研究, 本文主要采用预加重、分帧加窗(Petmezas et al, 2022)、幅值规整的方式进行鸟声信号数据预处理。
本文经过Box 1中的步骤对鸟声音频进行预处理, 得到多段时间信号序列(x1, x2,…, xn), 这些序列为特征提取的输入。
Box 1 鸟声数据集处理流程
1. 输入鸟声音频原始的WAV格式文件;
2. 将数据文件切分为5 s每段的音频文件, 采样率为32 kHz;
3. 将音频的信号值以0.97的倍率进行预加重, 计算各采样点的信号值变化;
4. 使用50%重叠的汉明窗对连续采样点分帧加窗, 得到多段近似平稳时间信号序列。
1.1.1 预加重
各类鸟声信号中包含着较为丰富的低频成分, 而高频成分较少。为了得到稳定的信号特征, 需将其高频进行提升。这一方面是由信号本身的特点所决定的, 另一方面主要是由于信号在传播的过程中高频成分衰减率要比低频高。为了加强高频特征在信号特征提取中的作用, 尤其重要的是对远距离传播的信号进行高频提升。设
其中
1.1.2 分帧加窗
数据集中各类别鸟声音频长度长短不等且数量不均, 这使得鸟声识别过程困难重重(Dai et al, 2021)。并且由于音频信号长期呈现出的非平稳性, 使得不能采用一般信号处理的手段来分析。在10‒30 ms时间内, 信号可被视为平稳信号。所以可以通过对预加重后的鸟声信号y(n)加以分帧来解决这个问题, 分帧可以将一段未知长度的音频数据分割成许多固定长度的片段y1(n), y2(n),…, yk(n), 即取固定值的采样点
1.2 特征提取
在深度学习领域, 特征的选择和提取发挥着越来越重要的作用, 一个好的特征有时甚至要比一个好的模型更为关键。低层特征包含原始数据中的更多信息, 但是经过的操作少, 包含的噪声信息更多; 高层信息包含噪声少, 但是可能在提取过程中损失掉关键信息。融合不同尺度的特征是一种特征提取的新思路。
1.2.1 梅尔谱系数
特征的具体提取流程和计算过程如下:
(1)预加重、分帧、加窗。确定经过预处理后的鸟声信号每一帧的采样点数n。
(2)时频转换。利用基础的离散傅里叶变换将每帧的时域信号
(3)使用梅尔滤波器组进行过滤。根据信号幅度谱
(4)对数操作。由于正常人耳对声音的整体感觉并不完全是线性的, 利用对数这种非线性向量关系可以更好地模拟人耳所能得到感知的声音过程。
经过对数操作的梅尔谱系数存在相关性, 为了避免在一些机器学习算法中预先假设数据导致的不相关, 研究者们则提出使用离散余弦变换(discrete cosine transform, DCT)对梅尔谱系数进行压缩得到一组不相关的梅尔频率倒谱系数。但经过复杂的神经网络架构, 在训练的过程中可以将相关性的问题弱化, 同时DCT作为一种线性变化有可能会损失信号中的一些非线性信息, 所以在本文中舍弃了DCT变换, 从而直接提取梅尔谱系数。梅尔谱系数提取流程如图2所示。
图2

1.2.2 特征融合
由于梅尔谱系数的鲁棒性较差, 为了使特征更能体现时域连续性, 可以在特征维度增加前后帧信息。所以选择加入该特征时间维度上提取的一阶、二阶差分做补充, 与原梅尔谱系数特征一同组成融合特征, 提高对信号噪声的处理效果。差分参数是当前帧的前两帧和后两帧的线性组合。
本文将经过预处理的梅尔谱系数同经过差分的梅尔特征进行拼接(concat), 从而得到一个新的融合特征, 这个特征中既包含了原始信号梅尔谱系数, 使得后续的机器学习模型可以从中直接提取到适合用于分类的特征, 也包含了在语音识别中表现良好的高维对数梅尔谱差分特征。因为该融合特征通过融合方式包含了鸟声数据原始时频信息以及模拟人耳听觉感官得到的信息, 使得它能够从多个角度对鸟鸣声信号数据加以表达。对鸟鸣声信号特征处理提取并融合的全过程如图3所示。假设两个输入特征x和y的维数为p和q, 则输出特征z的维数为p + q。
图3
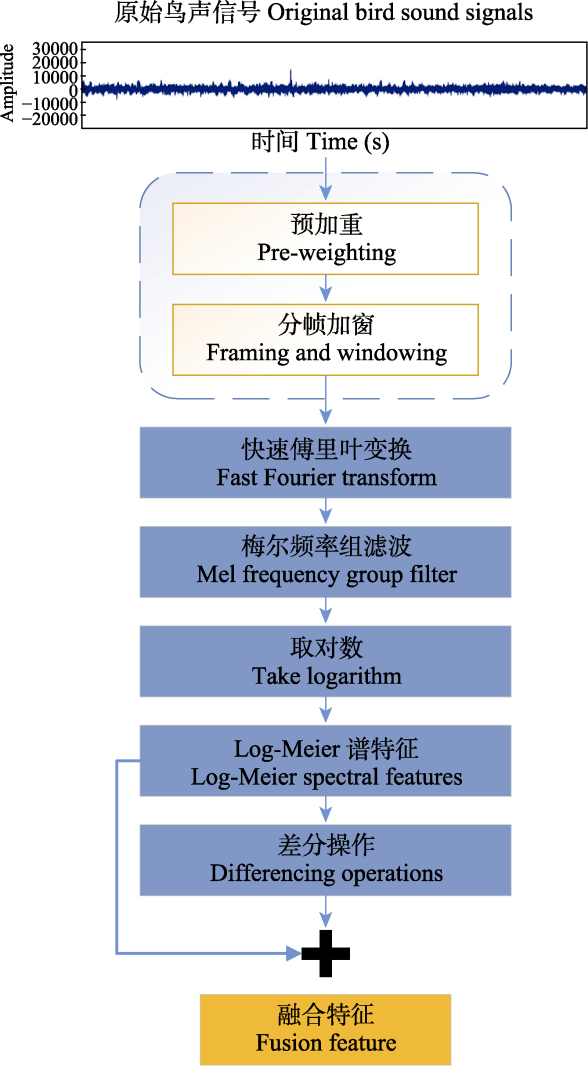
图3
鸟鸣声特征提取与融合流程图。
 为拼接(concat)操作, 即直接将两个特征进行连接。
为拼接(concat)操作, 即直接将两个特征进行连接。
Fig. 3
Bird chirp feature extraction and fusion flow chart.
 means concat operation, which is connecting two features directly.
means concat operation, which is connecting two features directly.
通过预处理和特征提取, 得到了可以直接输入到分类模型中的三维特征矩阵(Box 2), 矩阵的输入特征为三通道, 使用一阶差分作为第二通道特征, 使用二阶差分作为第三通道特征。
Box 2 融合特征提取流程
输入: 音频时间信号序列组(
1. 输入5 s鸟声音频段的时间信号序列帧;
2. 对每帧信号经过短时傅里叶变换得到信号的频谱特征;
3. 计算经过60阶的梅尔频率组的输出的对数能量和;
4. 计算一阶差分、二阶差分;
5. 将梅尔谱特征、梅尔一阶差分值与梅尔二阶差分值拼接组成融合特征。
输出: 三维特征矩阵[
1.3 神经网络架构设计
1.3.1 网络结构
DenseNet是一种卷积神经网络结构(Huang et al, 2017), 主要包含卷积层(convolutional layer)、密集块(dense block)、过渡层(transition layer)和分类器(classifier)。它采用的是密集连接机制, 以前馈(feedforward)方式与各个密集块中的层直接连接。它把前面所有层特征图的输出均作为当前层的输入。密集连接的方式使得网络能够同时挖掘空间域与时间域的特征, 并且所使用的注意力机制能够帮助网络聚焦重要特征, 减少无关信息的干扰。由此解决梯度消失的问题, 提升所提框架性能。本文采用DenseNet121模型, 该模型总共包括4个密集块和121个层。网络中的每一层均以紧密连接的方式与随后的所有层相连, 最后是将
图4
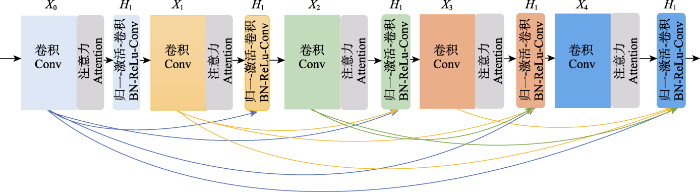
图4
Attention-DenseNet网络结构图。
Conv: 卷积层; BN: 批量归一化; ReLu: ReLu激活函数。
Fig. 4
Attention-DenseNet structure diagram.
Conv, Convolutional layer; BN, Batch normalization; ReLu, ReLu activation function.
1.3.2 自注意力模块
在一段音频中所包含的声音可能包含背景噪声、风声等非兴趣噪声, 为了让网络关注所感兴趣的鸟声部分, 此处引入注意力模块进行兴趣区域聚焦。
图5
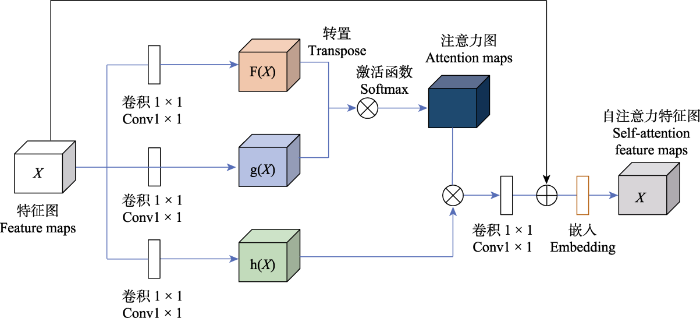
首先, 通过3条分支分别使用1 × 1卷积对输入的特征图进行通道压缩, 使其通道维度压缩为一维, 由此减少无关信息冗余, 提高后续计算速度。然后, 在F(X)分支输出的特征图上进行转置操作, 并将结果转置后的结果与g(X)分支的输出特征进行矩阵相乘, 接着使用softmax对其进行归一化。在这一过程中, 向量间的余弦相似度通过矩阵乘积进行表征, 乘积的结果即表示为特征图间的相似度。最后, h(X)分支的特征图与归一化后的注意力矩阵进行相乘, 得到最后的特征图。根据类内相似度在通道维度上进行权重的加权重分配, 接着将结果输入softmax函数中, 并且使用1 × 1卷积核对输出结果进行处理, 使其通道数与输入特征图的通道保持一致。通过这种方式, 输出的特征经过注意力机制进行了权重重分配, 使其能够充分表达。
最后, 为了优化系统在高维特征检索时的时间开销(time consuming)及存储上的空间开销(space consuming), 本文采用主成分分析法(PCA)对高维特征进行降维, 最终输出能够高效表征图像特征的128维特征向量。
1.3.3 中心损失函数
在进行音频采集时, 同类别的鸟鸣声数据会因其采集方式、环境因素、个体特征等易出现较大的差距, 从而导致在类间识别时由于类内特征过于分散而相互混杂。故而本文使用了两种损失函数相结合的方法来改善上述问题。损失函数(L)计算公式如下:
为了解决类内特征不紧凑的问题, 本文引入了中心损失, 使用超参数公式v控制
2 案例分析
2.1 数据集获取
本文实验所采用的模型训练鸟类音频文件数据集全部来自Xeno-Canto世界野生鸟类声音公开数据集(
表1 本研究所采用的模型训数据集说明
Table 1
| 鸟类中文名称 Chinese name | 鸟类英文学名 Latin name | 库内标签 Registered label | 样本时长 Sample length (s) | 数据来源 Data source |
|---|---|---|---|---|
| 美洲麻鳽 | Botaurus lentiginosus | amebit | 23,960.7 | |
| 白头海雕 | Haliaeetus leucocephalus | baleag | 22,744.8 | |
| 布氏雀鹀 | Spizella breweri | brespa | 23,880.6 | |
| 普通拟八哥 | Quiscalus quiscula | comgra | 23,517.5 | |
| 角鸬鹚 | Phalacrocorax auritus | doccor | 22,183.7 | |
| 灰斑鸠 | Streptopelia decaocto | eucdov | 22,837.2 | |
| 长嘴啄木鸟 | Leuconotopicus villosus | haiwoo | 23,009.2 | |
| 暗背金翅雀 | Spinus psaltria | lesgol | 22,521.4 | |
| 环颈潜鸭 | Aythya collaris | rinduc | 21,653.2 | |
| 白喉雨燕 | Aeronautes saxatalis | whtswi | 22,491.7 |
3.2 训练结果分析
本实验在ubuntu操作系统中运行, 使用显卡为NVIDIA-3080、并配备32G内存。编译器为PyCharm, 并在其中使用Pytorch框架完成神经网络架构设计。本实验以多种鸟类声音分类为研究背景, 对测试集的13,728个样本、10个类别进行分类识别。使用基于注意力机制的DenseNet模型进行实验, 模型使用的参数见表2。
表2 DenseNet模型参数列表
Table 2
| 参数名称 Parameter name | 参数值 Parameter value |
|---|---|
| 批大小 Batch_size | 256 |
| 时期数 Epochs | 50 |
| 学习率 Learning rate | 0.001 |
| 优化器 Optimizer | 自适应矩估计优化器 Adam optimizer |
| 损失函数 Loss function | 分类交叉熵 Categorical_cross-entropy |
(1)特征效果对比分析。融合特征是将改良后的对数梅尔谱差分特征同原始信号拼接所得的特征。分别利用原始特征、对数梅尔谱差分特征和融合特征在VGG11、ResNet18和DensNet121模型中进行对比实验, 测试特征效果。测试结果见表3, 表中显示了融合特征在Densnet121和VGG11模型下准确率最高。
表3 VGG11、ResNet18与DensNet121采用不同特征准确率对比。加粗数值为使用融合特征所得的准确率。
Table 3
| 特征提取方法 Feature extraction method | 准确率 Accuracy | 总参数量 No. of parameters |
|---|---|---|
| VGG11 + 原始特征 VGG11 + Original feature | 0.906 | 1.38e8 |
| VGG11 + 对数梅尔谱差分特征 VGG11 + Log-Meier spectral differential characteristics | 0.926 | 1.38e8 |
| VGG11 + 融合特征 VGG11 + Fusion feature | 0.935 | 1.38e8 |
| ResNet18 + 原始特征 ResNet18 + Original feature | 0.896 | 1.11e7 |
| ResNet18 + 对数梅尔谱差分特征 ResNet18 + Log-Meier spectral differential characteristics | 0.912 | 1.11e7 |
| ResNet18 + 融合特征 ResNet18 + Fusion feature | 0.933 | 1.11e7 |
| DensNet121 + 原始特征 DensNet121 + Original feature | 0.901 | 6.94e6 |
| DensNet121 + 对数梅尔谱差分特征 DensNet121 + Log-Meier spectral differential characteristics | 0.932 | 6.96e6 |
| DensNet121 + 融合特征 DensNet121 + Fusion feature | 0.939 | 6.96e6 |
表3中可以看出融合特征在VGG11、ResNet18和Densnet121模型的准确率都在93%以上, 虽然准确率相差不大, 但是在参数方面DensNet121的总参数远远小于其他两个模型, 从综合考虑DensNet121具有空间复杂度低, 为此本文选择DensNet121作为基础模型。
(2)消融实验分析。为了体现本文所提到改进点的有效性, 本文通过消融实验对比, 并对结果进行分析。通过对比改进点在3种经典网络框架上的应用结果, 选取最适用于针对本文数据的框架结构。具体为以下三点: 一是原始特征和对数梅尔谱差分特征进行融合特征; 二是加入自注意力模块, 强化音频信号中关键细节特征的表达能力; 三是使用softmax loss和center loss结合优化, 在加大类间距离的同时, 缩短类内距离, 使样本特征在特征空间的分布更加合理。具体实验结果如表4, 本文使用的方法在测试集数下准确率达到了96.9%。
表4 基于DenseNet121的对比实验
Table 4
| 模型 Model | 准确率 Accuracy |
|---|---|
| DensNet121 + 融合特征 DensNet121 + Fusion feature | 0.939 |
| DensNet121 + 融合特征 + 注意力机制 DenseNet121 + Fusion feature + Attention | 0.953 |
| DensNet121 + 融合特征 + 注意力机制 + 中心损失函数 DenseNet121 + Fusion feature + Attention + Center loss function | 0.969 |
本文提出的模型对鸟声数据集提取得到的DensNet121 + 融合特征 + 注意力机制 + 中心损失函数测试过程的性能变化曲线, 如图6所示。
图6
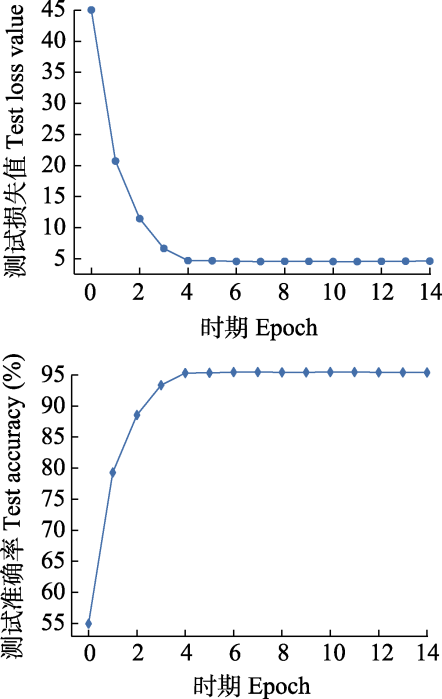
图6
实验测试损失值与识别准确率。
上图为0‒14时期损失值点图, 下图为0‒14时期准确率点图。
Fig. 6
Experimental test loss value and recognition accuracy.
The above figure is the dot plot for the loss values of 0‒14 epochs, and the figure below is the dot plot for the accuracies of 0‒14 epochs.
从图6可以看出该模型在前10轮次(Epoch)快速达到训练最优解, 收敛速度变慢趋于平稳, 最终在训练集上的准确率达到96.9%, 损失接近于1%。
3 结论
本文从特征提取技术和设计模型对所做主要工作加以验证和评估, 并通过对比实验结果进行评估分析, 实现鸟声信号的目标识别。同时验证了改良后的对数梅尔谱差分参数同原始信号参数拼接所得的特征方法, 该方法有效地提升了鸟声目标分类的准确率。最后, 评估结果在构造的数据集上进行测试, 在测试集上准确率达到96.9%, 实验验证了所提出模型的有效性与可行性。所有代码已开源至Github:
参考文献
Non-local means denoising
DOI:10.5201/ipol.2011.bcm_nlm URL [本文引用: 1]
Understory vegetation in planted pine forests governs bird community composition and diversity in the eastern Mediterranean region
DOI:10.1186/s40663-019-0186-y URL [本文引用: 1]
Blind source separation-based IVA-Xception model for bird sound recognition in complex acoustic environments
DOI:10.1049/ell2.12160 URL [本文引用: 1]
Deep residual learning for image recognition
Densely connected convolutional networks
Bird sound recognition using a convolutional neural network
ImageNet classification with deep convolutional neural networks
DOI:10.1145/3065386 URL [本文引用: 1]
Research on bird recognition method based on bird singing and deep learning
基于鸟鸣声及深度学习的鸟类识别方法研究
Application of appropriate technology for automatic bird pest removal and automatic fish feed in the Minapadi system in Beutong Nagan Raya District
DOI:10.51601/ijcs.v1i3.38 URL [本文引用: 1]
Automated lung sound classification using a hybrid CNN-LSTM network and focal loss function
Research on railway intelligent bird repellent based on sensor technology and Internet of Things technology
基于传感器技术和物联网技术的铁路智能驱鸟器的研究
Diversity of bird community in spring in Bodhi Islands, Hebei Province
河北菩提岛诸岛春季鸟类群落多样性
Convolutional neural network-gated recurrent unit neural network with feature fusion for environmental sound classification
DOI:10.3103/S0146411621040106 URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}