|
|
||||||||||||||||||||||||||||||||
|
基于GenBank数据库的真核生物遗传数据时空格局分析
生物多样性
2025, 33 (8):
25184-.
DOI: 10.17520/biods.2025184
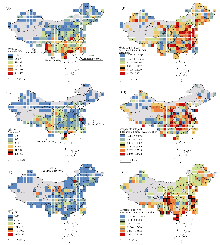
遗传数据在生物多样性研究和保护实践中发挥着越来越重要的作用, 然而研究者应用这些数据时常面临数据质量缺陷、地理或类群分布不均等方面的制约, 尽管陆生脊椎动物的遗传数据格局已有较深入研究, 但全球植物、真菌和其他动物类群的遗传数据空间分布模式仍缺乏系统的实证研究。本文采用多尺度分析方法, 系统评估了动物、植物和真菌三大真核生物界的遗传数据现状、元数据完整性以及遗传数据的时空动态趋势。结果表明, 动物界拥有约2.7亿条序列和1.6万个基因组数据, 超过植物界(约1.4亿条, 0.7万个)和真菌界(约0.2亿条, 1.7万个)。遗传数据的地理元数据缺失现象普遍存在, 其中真菌ITS序列的经纬度缺失最为严重(缺失率92.07%), 其次是植物rbcL (83.19%)和动物COI (26.40%)。时空分布格局显示, 全球尺度上遗传数据呈现明显的“北半球中心化”特征, 北美、西欧和东亚地区占据主导地位, 而南半球普遍数据匮乏; 同时观察到动物COI和植物rbcL数据呈下降趋势, 而真菌ITS数据快速增长。中国区域则表现出独特的“南动物、东植物、北真菌”分布格局, 而西北地区数据积累明显不足; 时间维度上, 中国植物和真菌数据持续增长, 而动物数据保持稳定。这些发现揭示了遗传数据质量缺陷和分布失衡已成为制约生物多样性研究的重要瓶颈。为此, 我们建议建立严格的元数据存档标准, 重点加强南半球和中国西北部等数据薄弱区域的科研投入, 并通过构建国际科研合作网络促进全球数据资源的均衡配置, 从而提升遗传数据在生物多样性研究和保护实践中的应用价值。
表1
动物界、植物界和真菌界的代表性序列统计
正文中引用本图/表的段落
为探究三大真核生物界序列数据在全球及中国尺度的时空格局, 本研究基于R软件的raster、sp、rgdal和rgeos等空间分析包, 对动物COI、植物rbcL和真菌ITS序列的空间分布格局及时间变化趋势进行了系统分析。本研究采用三级空间分析体系, 在全球尺度构建4° × 4°网格, 在中国尺度则采用2° × 2°更高分辨率网格, 同时基于标准国界世界地图进行国家尺度分析。所有空间数据均采用WGS84地理坐标系(EPSG:4326)以确保空间分析结果的一致性和可比性。在国家尺度分析中, 我们整合了包含有效经纬度的高精度数据集和具有国家名称或有效经纬度的全数据集, 这种双重数据整合方式既能充分利用现有序列数据资源, 又能提高国家序列分布格局分析的准确性, 此外, 通过对两类数据的系统对比, 可以评估仅使用高精度数据对序列分布格局分析结果的影响。在网格水平空间分布格局分析中我们使用了高精度数据集, 而在时间变化趋势分析中我们使用了时间序列数据集, 该数据集在高精度数据集的基础上剔除了采样时间缺失以及2000年以前的序列数据(动物约占4.70%、植物约占5.29%、真菌约占3.81%), 主要基于以下考虑: 首先, 2000年前的数据在三大类群中占比较低且时间跨度长达72-75年, 这种稀疏且离散的分布模式会严重影响时间序列分析的统计效力; 其次, 2000年后高通量测序技术的广泛应用显著提升了数据的标准化程度和质量稳定性。这一截断标准在保证数据代表性的同时, 有效优化了时空格局分析的可靠性。在此基础上, 我们定量统计了各网格总序列数, 通过构建每个网格的年际序列数量线性回归模型(以年份为预测变量, 年际序列数为响应变量), 计算得到标准化相关系数来量化网格内序列的年际变化趋势, 该指标取值范围为[-1, 1], 其中正值表示序列数量呈增长趋势, 负值表示呈下降趋势, 且绝对值越大表明年份与序列数量之间的统计关联性越强。同时, 使用t检验评估相关系数的显著性(P值), 以判断观测到的趋势是否具有统计学意义。最后通过ArcMap V10.7分别绘制了三大真核生物界序列数量的空间分布格局和年际变化趋势图, 基于自然断点法(Jenks natural breaks) (Jenks, 1967)将网格序列总数和年际变化相关系数划分为6个等级梯度进行展示, 并通过黑色网格边框突出相关系数显著的区域(P < 0.05)。本研究使用的所有代码已上传至Gitee数据库(
本研究系统评估了三大真核生物界代表序列的数据完整性(表1)。结果显示, 动物COI元数据质量最优: 在下载到的360万条COI序列中, 58.95%的序列包含完整时空信息; 植物rbcL和真菌ITS分别仅有9.16%和3.42%的序列符合标准。值得注意的是, 植物rbcL和真菌ITS的经纬度缺失率分别高达83.19%和92.07%, 远高于动物COI (26.40%)。数据清洗过程中, 各类群的异常经纬度剔除率分别为: 9.95% (动物COI)、2.36% (植物rbcL)和0.70% (真菌ITS)。相较于高精度数据集, 使用全数据集时, 可用于动物、植物和真菌三大真核生物类群国家尺度分析的序列比例分别提高到86.44%、57.61%和63.61%。
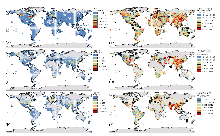
全球真核生物代表序列的时空格局分析表明, 遗传数据既存在明显的地理偏倚, 又展现出不同类群间的时间动态差异(图1)。在空间分布方面, 三大类群均呈现明显的区域聚集现象, 动物COI序列主要富集于北美和西欧地区, 其中多伦多(18.01%)、班夫国家公园(12.74%)和瓜纳卡斯特国家公园(5.32%)周边网格最为密集(图1A); 植物rbcL数据也集中分布于瓜纳卡斯特国家公园(8.13%)和多伦多(8.27%)附近网格(图1C); 而真菌ITS数据分别在印度南部(4.24%)、中国北部(3.40%)、加拿大西南部(3.23%)以及墨西哥南部(3.88%)网格呈现局部聚集(图1E)。
本研究发现不同生物类群间的地理元数据缺失存在显著差异, 其中真菌ITS的缺失最为严重, 仅有7.93%的序列包含地理元数据, 这一现象主要源于以下原因: 首先, 真菌的微观特性(Hawksworth, 2001)使其难以像动植物那样通过直观形态特征进行野外识别和记录。其次, 真菌分类主要依赖于基于分子数据构建的系统发育树(Taylor et al, 2000), 而现有生物多样性数据库主要针对大型生物的形态分类体系设计(Meineke et al, 2018)。此外, 相比动植物通过标本馆、博物馆以及公民科学平台建立的长期数据积累(Brown & Williams, 2019), 真菌样本的采集历史较短且分散, 这些因素使得真菌在元数据整合过程中面临更大挑战(Harris et al, 2023)。值得注意的是, 这种元数据缺失问题并非真菌所特有。尽管动植物具有更完善的分类体系和数据积累, 但动物COI和植物rbcL序列仍存在严重的地理元数据缺失, 缺失率分别为26.40%和83.19% (表1), 这种跨类群的普遍现象暗示着更深层次的问题: 地理元数据缺失并非简单的技术疏漏, 而是与研究习惯、类群特性和数据管理规范密切相关的系统性缺陷。更为重要的是, 地理元数据的缺失往往只是冰山一角, 它通常与采样时间、海拔、寄主等重要元数据的遗漏同时存在, 这种多维度的信息断层会产生连锁反应: 一方面使得物种的环境适应性分析失去时空参照系, 导致生态位模型无法进行有效预测; 另一方面也严重制约了分子数据在生物多样性监测和保护实践中的应用, 当条形码数据缺乏配套的生态背景信息时, 其在入侵物种预警(Gaither et al, 2013)、划分遗传多样性热点地区(Wood et al, 2013)和濒危物种保护(Fallon, 2007)等关键领域的决策支持价值将大打折扣, 最终可能造成科学研究与保护实践之间的“数据鸿沟”。要解决这些问题, 亟需采取以下措施: 首先, 应建立期刊和科研机构的强制性元数据共享政策(Vines et al, 2013), 要求研究者提交数据时严格遵守FAIR原则, 同时优化数据共享平台的功能设计, 通过简化操作流程、提供标准化模板等方式, 降低研究者提交完整元数据的操作门槛(Deck et al, 2017; Riginos et al, 2020)。特别是对于真菌这类元数据缺失严重的类群, 建议开发专门的元数据采集工具, 确保野外采样时能准确记录样本的采集地点、时间、生境特征等关键信息。其次, 需要加强科研人员的元数据管理意识, 通过开展专题培训和建立激励机制, 鼓励研究者主动补充缺失的元数据以填补先前的数据空缺。最后, 应重点加强对数据缺失类群特别是真菌研究的支持力度, 通过设立专项研究计划系统性地填补关键类群的数据缺口, 同时构建专门针对真菌研究的分子数据库, 充分考虑其生物学特性设计专门的元数据字段, 并积极开发智能化工具来实现元数据的自动提取与关联整合。这一系列协同措施将显著提升遗传数据在生物多样性保护实践和可持续利用中的科学价值与应用潜力。
值得注意的是, 元数据缺失与数据地理偏倚之间存在双向强化关系: 元数据缺失不仅掩盖了真实的地理分布格局, 其本身往往就是地理偏倚的必然产物。具体而言, 科研资源长期向特定生物类群和地区倾斜, 导致这些优势类群和地区的数据采集与记录相对规范完整; 而其他类群和地区则因缺乏研究投入而持续处于“数据缺失-研究忽视”的困境。这种系统性偏差在全球尺度的遗传数据分布格局中表现得尤为明显: 我们的分析显示, 遗传数据分布在全球尺度上呈现出典型的“北半球中心化”分布特征, 北美、西欧和东亚地区的遗传数据量占据绝对优势, 而南半球大部分地区普遍处于数据匮乏状态(图1)。其中加拿大多伦多周边区域表现出异常的数据集中现象, 这一分布格局的形成可归因于以下几个关键因素: 首先, 多伦多作为国际条形码数据库BOLD (Barcode of Life Data System)的创始地(Ratnasingham & Hebert, 2007), 当地科研机构开展了长期且系统性的区域生物多样性调查, 从而积累了大量的本地物种条形码数据。其次, 该地区作为全球重要的测序中心, 承担了大量国际样本的测序工作, 但在数据记录过程中, 部分样本的真实地理信息可能被简化为测序机构所在地坐标。这些结果表明, 当前全球生物多样性监测网络存在着严重的地理偏倚, 这种偏倚既反映了科研资源配置的区域差异, 也暴露出数据采集和标注过程中的系统性偏差。值得注意的是, 由于真菌数据存在高达92.07%的地理信息缺失率, 因此现有分析可能无法真实反映真菌多样性的实际分布特征。在时间动态方面, 动物COI和植物rbcL数据呈现下降趋势, 可能反映了北美和西欧等传统研究热点区域的采样饱和现象; 相比之下, 真菌ITS数据持续增长, 特别是在东亚等新兴研究区域(图1)。这一趋势可能得益于环境DNA和宏条形码技术的广泛应用(Yan et al, 2018)以及真菌在生态监测中重要性的提升(Warnasuriya et al, 2023)。
本文的其它图/表
|