鸟声标注技术及其在被动声学监测中的应用
郭倩茸, 段淑斐, 谢捷, 董雪燕, 肖治术
生物多样性
2024, 32 ( 10):
24313-.
DOI: 10.17520/biods.2024313
鸟声标注用于标记声音中的鸟类信息, 如种类、声音结构等, 是鸟类被动声学监测及相关声学数据分析、物种自动识别分类的重要基础。本文以鸟声标注为重点, 比较了人工标注、自动标注和半自动标注等常用方法的优势, 点明了各自在数据质量、标注一致性和标注效率等方面面临的挑战, 同时探讨了这些标注方法在被动声学监测中的应用进展, 提出了自动标注模型优化、跨地区数据集建立和半自动标注系统完善等未来发展方向。尽管目前自动标注方法取得了显著进展, 但鸟声标注仍面临冷启动问题, 亟需更大规模的跨地区数据集和高效的质量检测半自动标注系统, 以满足标注数量和质量的双重要求。本综述有助于帮助鸟声数据集创建者和标注者更好地理解现有标注技术及其潜在的发展趋势, 为大规模鸟类声学监测数据的高效物种自动识别提供技术支撑。
View image in article
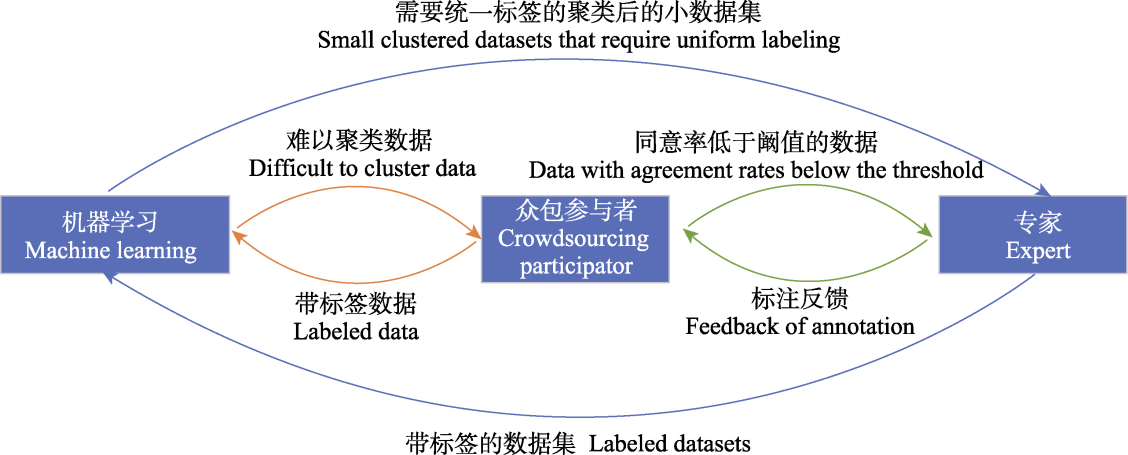
图2
双循环半自动标注法(修改自Méndez Méndez et al, 2024)
正文中引用本图/表的段落
Méndez Méndez等(2019)提出新的标注模型(图2), 包含前向循环(机器→众包参与者→专家)和后向循环(机器→专家→众包参与者)。前向循环可提高标签的质量, 后向循环可促进用户学习以及提高用户参与度, 并且详细描述使用模型时的标注步骤(Méndez Méndez, 2024)。双循环系统中, 前向循环机器学习将难以聚类的数据留给众包, 众包参与者通过多数投票机制提供标签, 如果同意率低于阈值,再由鸟类专家进行标注, 专家赋予标签后传递给模型学习。后向循环将聚类后的数据集提供给专家, 附上数据集统一标签, 专家给众包志愿者提供标注反馈, 提升参与者的专业知识, 如果志愿者的专业度提升, 可以减少时间成本和邀请专家的资金。众包参与者提供标签之后将带标签的数据集传递给模型, 继续模型训练。为了证实双循环标注模型的有效性, 研究人员将其应用于SONYC-UST数据集, 为该城市噪音数据集中的音频提供了标签(Cartwright et al, 2019)。
深度神经网络可显著提升声音识别的性能, 但网络参数随着层数的增加显著增长, 并且在不同环境下的识别效果是不同的(Pahuja & Kumar, 2021).卷积神经网络中的经典模型有LeNet-5 (LeCun et al, 1998)、AlexNet (Krizhevsky et al, 2017)、VGG16 (Simonyan & Zisserman, 2014)、Inception (Szegedy et al, 2015)、ResNet (He et al, 2016)、DenseNet (Huang et al, 2017)、EfficientNet (Tan & Le, 2019), 模型输入信号可以为人工特征也可以为原始音频, 并且识别鸟类发声效果比较好, 但是只能提取短时间帧的特征, 不能获取相邻帧之间的顺序特征.卷积递归神经网络(convolutional recurrent neural networks, CRNN)虽然可以获得时间帧之间的顺序相关性, 但CS-CLDNN (Convolutional Block Attention Module -Switch-CNN-LSTM-DNN) (Xie et al, 2022)、长短时记忆递归神经网络(long short term memory, LSTM)、门控循环单元(gated recurrent unit, GRU)、勒让德记忆单元(Legendre memory unit, LMU)等典型CRNN结合了卷积神经网络和递归神经网络, 需要大量的计算资源.支持向量机(颜鑫和李应, 2013)、K最近邻(Joly et al, 2014)、决策树(Lasseck, 2015)、隐含马尔柯夫模型(Ntalampiras, 2018)、球形K均值(Salamon et al, 2017)、变分编码器(吴科毅等, 2023)等方法也是典型鸟声识别方法.隐含马尔柯夫模型在非平稳噪声下的识别效果差, K最近邻弱监督学习容易导致标注噪声, 使用决策树方法时特征选择过程比较复杂.当标注数据较少时, 可使用基于半监督学习的识别方法, 比如高斯混合模型(Gaussian mixture model, GMM) (Ptacek et al, 2016)、孪生神经网络(siamese neural networks, SNNs) (Acconcjaioco & Ntalampiras, 2021)等算法.由于模型的结构、特征的选择、预处理等都会影响模型识别效果, 研究人员通常选择特征融合(Zhang et al, 2021; Wang et al, 2022)、关联多个分类器(Gupta et al, 2021)、选择合适的层数和卷积核(Kahl et al, 2021)、增加注意力机制(Xie et al, 2020, 2022)等方法提升识别效果.Zhang等(2021)分别采用短时傅里叶变换、梅尔频率倒谱变换和Chirplet变换生成频谱图, 并逐个训练单特征识别模型, 最终形成特征融合模型, 使得模型识别精度提升.Gupta等(2021)的实验结果表明, 卷积神经网络和循环神经网络(recurrent neural networks, RNN)结合起来的模型分类性能高于单独的卷积神经网络模型.Kahl等(2021)提出的BirdNET网络由127层2,700万个参数组成, 在单物种记录方面的平均精度为0.791.Xie等(2022)在CLDNN (CNN-LSTM-DNN)模型中引入卷积注意力机制, 使其分类性能提高. ... Exploring the application of acoustic indices in the assessment of bird diversity in urban forests 1 2023 ... 被动声学监测数据的标注在生态声学研究中扮演了关键角色.不同的研究目的需要不同的标注方法和标签, 以满足数据分析的需求.种群分析中标注不能仅限于物种, 还需要包括与环境、季节和时间等因素相关的信息.郭安琪等(2022)利用被动声学监测技术在海南热带雨林国家公园霸王岭片区采集了连续9个月的海南长臂猿(Nomascus hainanus)的声学数据, 标注了鸣叫节律, 并进一步分析了这些节律与温度、湿度、降水量和太阳净辐射4个气象因子的关系.边琦等(2023)对城市森林的50个调查地点进行了声景采集分析, 通过标注物种等标签, 发现声音的多样性指数与鸟类的丰富度高度相关.Wang等(2012)应用被动声学监测技术研究了海南热带雨林大树蛙(Zhangixalus dennysi)繁殖期的合唱行为, 发现雄蛙可以根据温湿度的变化调节它们的发声行为.种群识别关注物种标签, 通过标注特定物种的声音可以实现物种自动识别, 例如王虎诚等(2023)在九里湖国家湿地公园基于被动声学监测技术收集的野外鸟鸣声数据研究了物种的自动识别.行为识别关注物种标签和行为类型, 如华铣泽等(2020)研究高原鼠兔(Ochotona curzoniae)时, 通过标注不同类型的长鸣声, 区分出其示警、求偶和领域鸣声.对于个体识别, 标注工作更加细致, 通常包括个体间的鸣声差异、年龄、性别等信息.Chen等(2020)通过标注个体内部的声音特征, 研究了动物种内识别.这样的细致标注在珍稀物种保护中尤为重要, 通过专家标注, 可以提供动物个体精确的活动时间、行为特征和生态习性标签, 帮助生态学家评估物种对环境变化的响应.综上所述, 研究人员使用被动声学监测数据, 可在物种鸣声自动识别(Clark et al, 2023)和声景研究(LeBien et al, 2020)两个方面评估野生动物, 以研究生物多样性和生态环境现状.生态声学研究关注声学群落的整体状态变化, 可以采用自动标注方法标注音频数据中动物群体的物种、活动力度等标签, 众包参与者检查验证自动标注生成的标签, 通过标签计算生态声学指数(Colonna et al, 2020), 评估环境变化对生物的影响.如果研究人员关注个体差异或者群体差异, 比如珍稀物种保护项目中, 专家标注可提供关于动物个体的精确活动时间、行为特征和生态习性的详细标签.这些精细的数据对于生态学家来说可以揭示物种对环境变化的响应, 评估特定物种的保护状态, 甚至预测其未来的趋势. ... 声学指数在城市森林鸟类多样性评估中的应用 1 2023 ... 被动声学监测数据的标注在生态声学研究中扮演了关键角色.不同的研究目的需要不同的标注方法和标签, 以满足数据分析的需求.种群分析中标注不能仅限于物种, 还需要包括与环境、季节和时间等因素相关的信息.郭安琪等(2022)利用被动声学监测技术在海南热带雨林国家公园霸王岭片区采集了连续9个月的海南长臂猿(Nomascus hainanus)的声学数据, 标注了鸣叫节律, 并进一步分析了这些节律与温度、湿度、降水量和太阳净辐射4个气象因子的关系.边琦等(2023)对城市森林的50个调查地点进行了声景采集分析, 通过标注物种等标签, 发现声音的多样性指数与鸟类的丰富度高度相关.Wang等(2012)应用被动声学监测技术研究了海南热带雨林大树蛙(Zhangixalus dennysi)繁殖期的合唱行为, 发现雄蛙可以根据温湿度的变化调节它们的发声行为.种群识别关注物种标签, 通过标注特定物种的声音可以实现物种自动识别, 例如王虎诚等(2023)在九里湖国家湿地公园基于被动声学监测技术收集的野外鸟鸣声数据研究了物种的自动识别.行为识别关注物种标签和行为类型, 如华铣泽等(2020)研究高原鼠兔(Ochotona curzoniae)时, 通过标注不同类型的长鸣声, 区分出其示警、求偶和领域鸣声.对于个体识别, 标注工作更加细致, 通常包括个体间的鸣声差异、年龄、性别等信息.Chen等(2020)通过标注个体内部的声音特征, 研究了动物种内识别.这样的细致标注在珍稀物种保护中尤为重要, 通过专家标注, 可以提供动物个体精确的活动时间、行为特征和生态习性标签, 帮助生态学家评估物种对环境变化的响应.综上所述, 研究人员使用被动声学监测数据, 可在物种鸣声自动识别(Clark et al, 2023)和声景研究(LeBien et al, 2020)两个方面评估野生动物, 以研究生物多样性和生态环境现状.生态声学研究关注声学群落的整体状态变化, 可以采用自动标注方法标注音频数据中动物群体的物种、活动力度等标签, 众包参与者检查验证自动标注生成的标签, 通过标签计算生态声学指数(Colonna et al, 2020), 评估环境变化对生物的影响.如果研究人员关注个体差异或者群体差异, 比如珍稀物种保护项目中, 专家标注可提供关于动物个体的精确活动时间、行为特征和生态习性的详细标签.这些精细的数据对于生态学家来说可以揭示物种对环境变化的响应, 评估特定物种的保护状态, 甚至预测其未来的趋势. ... Bioacoustic classification of avian calls from raw sound waveforms with an open-source deep learning architecture 1 2021 ... 手动提取的人工特征主要有4种: 时域特征、频域特征、图像特征和时频特征.表3总结了常用的人工特征及其提取方法.常用的时域特征有短时过零率等(Marin-Cudraz et al, 2019), 频域特征有感知线性倒谱系数(Reynolds, 1994)等.单独的时域特征或者频域特征识别率低(Jin et al, 2023).研究人员使用声谱图提取特征, 比如图像频率统计(Bastas et al, 2012)、形状特征(Lee et al, 2013)等.时频特征是一种描述鸟鸣声时间和频率特征的方法, 提取时频特征的方法很多, 如离散小波变换(Sun et al, 2013)、小波包分解(Xie et al, 2016)、短时傅里叶变换(Mulimani & Koolagudi, 2019)、梅尔频率倒谱变换(Usman et al, 2020)等.为了提升识别效果, 可将多个时频特征进行融合(Zhang et al, 2021).鸟类交流中对于声音中的精细结构特别敏感, 但是手动提取的鸟声特征趋向于人类的理解, 可能忽略了鸟类声音的时序变化等重要特征(Dooling & Prior, 2017), 并且人工时频变换提取特征易造成信息损失, 使用卷积、长短期记忆深度神经网络(Sainath et al, 2015)、SincNet (Bravo Sanchez et al, 2021)等网络可以减少损失.一维卷积神经网络(Xie et al, 2021b)、自动编码器(Xie et al, 2020)、WaveNet (Van den Oord et al, 2016)等可以得到下游任务需要的特征, 与其他深度学习模型结合, 可实现更好的分类或者检测效果. ... Rank-loss support instance machines for MIML instance annotation 1 2012 ... 在自建数据集方面, Salamon等(2016)编制并公开了CLO-43SD数据集, 该数据集由来自43种不同种类的北美林莺的5,428个飞行呼叫音频片段组成.Bird-DB (Arriaga et al, 2015)数据集目前标注了428个文件, 关注鸟鸣声结构和上下文信息.HJA (Briggs et al, 2012)数据集包含从H.J. Andrews实验森林收集的10,232个鸟鸣声录音段, 其中4,998个已标记. ... The 9th annual MLSP competition: New methods for acoustic classification of multiple simultaneous bird species in a noisy environment 1 2013 ... 在附录1中, 公开数据集主要来源于鸟声识别挑战赛, 比如MLSP (Machine Learning for Signal Processing)、DCASE (Challenge on Detection and Classification of Acoustic Scenes and Events)等.这些比赛提供统一的数据集和评估指标, 以促进鸟声研究的发展.MLSP数据集由IEEE机器学习与信号处理国际会议发布, 包含美国俄勒冈州喀斯特山脉的H.J. Andrews实验森林中13个地点的19种鸟类, 共计645条10 s定长的.wav音频文件, 采样频率为16 kHz, 由专家根据原始数据和频谱图提供物种标签(Briggs et al, 2013; Koluguri et al, 2017; Narasimhan et al, 2017).ICML4B数据集由法国国立自然博物馆提供, 记录了法国巴黎舍夫勒斯地区自然公园的鸟声数据, 训练集包含35个30 s音频文件, 每个文件包含1个物种, 共35个物种(Go?au et al, 2014).测试集为90条150 s的音频文件, 采样频率为44.1 kHz.研究人员也从Xeno-canto、birder、Freesound等网站收集数据集.Xeno-canto是公认的数据来源网站, 包含450,000多条记录, 10,000多种鸟类, 包含采集地点、时间、记录评级等标签.研究人员通常可从多个网站下载数据, 比如Liu等(2022)从Xeno-canto和birder网站共收集30种鸟鸣声数据, 生成小波谱图.Zhang和Li (2015)从Freesound网站收集了30种鸟鸣声, 600个声音片段, 采样率为11.052 kHz.但Freesound网站收集的音频数据中噪声多, 适用于复杂环境下的鸟声研究.Hu等(2023)使用从Freesound网站收集的Urbansound8K数据集验证了分类模型的泛化能力, 该数据集是城市声音公共数据集, 包含27 h的音频, 有8,732个带注释的声音片段.此外, Macaulay自然声音博物馆、大英声音档案馆和柏林自然博物馆动物声音档案馆等也提供鸟声数据集.Macaulay自然声音博物馆有750,000份鸟类发声录音, 涵盖10,000多个物种. ... Designing interactions for robot active learners 1 2010 ... 自动标注的准确性主要取决于模型性能.如果模型性能不足, 就会产生不准确的标签.众包标注由于专业背景和目标的差异, 不能保证标注的数量和一致性.而且, 如果数据集过于庞大, 众包标注不仅低效且耗时.为了解决自动标注和众包标注方法中存在的问题, 研究人员综合两者的优势提出了半自动标注.半自动标注是通过主动学习(active learning, AL) (Settles, 2010), 使用机器学习方法得到比较“难”分类的样本数据, 再通过众包参与者确认和审核, 然后对人工标注的数据再次使用模型训练, 不断提升模型的效果.虽然可以减少人工标注的数据量, 但也存在标签质量问题.Callaghan等(2018)提出将专家纳入AL循环中.众包参与者通过多数投票的方法提供标签, 只要同意率低于阈值, 则询问鸟声专家确定标签.此框架中用户只需要表达同意还是不同意的意向, 用户的积极性不强(Cakmak et al, 2010). ... Mechanicalheart:A human-machine framework for the classification of phonocardiograms 1 2018 ... 自动标注的准确性主要取决于模型性能.如果模型性能不足, 就会产生不准确的标签.众包标注由于专业背景和目标的差异, 不能保证标注的数量和一致性.而且, 如果数据集过于庞大, 众包标注不仅低效且耗时.为了解决自动标注和众包标注方法中存在的问题, 研究人员综合两者的优势提出了半自动标注.半自动标注是通过主动学习(active learning, AL) (Settles, 2010), 使用机器学习方法得到比较“难”分类的样本数据, 再通过众包参与者确认和审核, 然后对人工标注的数据再次使用模型训练, 不断提升模型的效果.虽然可以减少人工标注的数据量, 但也存在标签质量问题.Callaghan等(2018)提出将专家纳入AL循环中.众包参与者通过多数投票的方法提供标签, 只要同意率低于阈值, 则询问鸟声专家确定标签.此框架中用户只需要表达同意还是不同意的意向, 用户的积极性不强(Cakmak et al, 2010). ... A dataset for benchmarking Neotropical anuran calls identification in passive acoustic monitoring 1 2023 ... 由于我国地域辽阔, 基于被动声学监测技术所建立的生物声学监测网络会在短时间内获得大量的数据.面对庞大的数据量, 研究人员需要重点关注自动标注技术.在训练自动标注模型时, 需要依赖专家标注提供高精度标签的训练集, 模型完成自动标注后, 还需要专家标注对生成的标签进行检查和验证, 并提供基准测试的数据集.目前, 有限人工标注的数据集限制了模型的学习能力, 大量自动生成的标签需要专家进行验证, 可以通过公民科学项目辅助验证, 但要考虑参与者的信誉度问题.在构建大尺度生物声学监测网络的同时, 建立完备的半自动标注系统是关键.该系统应使自动标注、专家标注和众包标注形成良性循环, 既提升模型的学习能力, 又减轻专家人工验证的压力, 并提升众包参与者的专业水平.该系统标注数据集应尽可能全面考虑研究方向, 标注的标签尽可能多, 例如, Ca?as等(2023)使用专家标注提供弱标签记录鸣声活动水平, 同时提供强标签记录有声段中不同物种鸣声的开始时间和信号质量. ... SONYC urban sound tagging (SONYC-UST):A multilabel dataset from an urban acoustic sensor network 1 2019 ... Méndez Méndez等(2019)提出新的标注模型(图2), 包含前向循环(机器→众包参与者→专家)和后向循环(机器→专家→众包参与者).前向循环可提高标签的质量, 后向循环可促进用户学习以及提高用户参与度, 并且详细描述使用模型时的标注步骤(Méndez Méndez, 2024).双循环系统中, 前向循环机器学习将难以聚类的数据留给众包, 众包参与者通过多数投票机制提供标签, 如果同意率低于阈值,再由鸟类专家进行标注, 专家赋予标签后传递给模型学习.后向循环将聚类后的数据集提供给专家, 附上数据集统一标签, 专家给众包志愿者提供标注反馈, 提升参与者的专业知识, 如果志愿者的专业度提升, 可以减少时间成本和邀请专家的资金.众包参与者提供标签之后将带标签的数据集传递给模型, 继续模型训练.为了证实双循环标注模型的有效性, 研究人员将其应用于SONYC-UST数据集, 为该城市噪音数据集中的音频提供了标签(Cartwright et al, 2019). ... Bird call identification using dynamic kernel based support vector machines and deep neural networks 1 2016 ... Artificial features and extraction methods
深度神经网络可显著提升声音识别的性能, 但网络参数随着层数的增加显著增长, 并且在不同环境下的识别效果是不同的(Pahuja & Kumar, 2021).卷积神经网络中的经典模型有LeNet-5 (LeCun et al, 1998)、AlexNet (Krizhevsky et al, 2017)、VGG16 (Simonyan & Zisserman, 2014)、Inception (Szegedy et al, 2015)、ResNet (He et al, 2016)、DenseNet (Huang et al, 2017)、EfficientNet (Tan & Le, 2019), 模型输入信号可以为人工特征也可以为原始音频, 并且识别鸟类发声效果比较好, 但是只能提取短时间帧的特征, 不能获取相邻帧之间的顺序特征.卷积递归神经网络(convolutional recurrent neural networks, CRNN)虽然可以获得时间帧之间的顺序相关性, 但CS-CLDNN (Convolutional Block Attention Module -Switch-CNN-LSTM-DNN) (Xie et al, 2022)、长短时记忆递归神经网络(long short term memory, LSTM)、门控循环单元(gated recurrent unit, GRU)、勒让德记忆单元(Legendre memory unit, LMU)等典型CRNN结合了卷积神经网络和递归神经网络, 需要大量的计算资源.支持向量机(颜鑫和李应, 2013)、K最近邻(Joly et al, 2014)、决策树(Lasseck, 2015)、隐含马尔柯夫模型(Ntalampiras, 2018)、球形K均值(Salamon et al, 2017)、变分编码器(吴科毅等, 2023)等方法也是典型鸟声识别方法.隐含马尔柯夫模型在非平稳噪声下的识别效果差, K最近邻弱监督学习容易导致标注噪声, 使用决策树方法时特征选择过程比较复杂.当标注数据较少时, 可使用基于半监督学习的识别方法, 比如高斯混合模型(Gaussian mixture model, GMM) (Ptacek et al, 2016)、孪生神经网络(siamese neural networks, SNNs) (Acconcjaioco & Ntalampiras, 2021)等算法.由于模型的结构、特征的选择、预处理等都会影响模型识别效果, 研究人员通常选择特征融合(Zhang et al, 2021; Wang et al, 2022)、关联多个分类器(Gupta et al, 2021)、选择合适的层数和卷积核(Kahl et al, 2021)、增加注意力机制(Xie et al, 2020, 2022)等方法提升识别效果.Zhang等(2021)分别采用短时傅里叶变换、梅尔频率倒谱变换和Chirplet变换生成频谱图, 并逐个训练单特征识别模型, 最终形成特征融合模型, 使得模型识别精度提升.Gupta等(2021)的实验结果表明, 卷积神经网络和循环神经网络(recurrent neural networks, RNN)结合起来的模型分类性能高于单独的卷积神经网络模型.Kahl等(2021)提出的BirdNET网络由127层2,700万个参数组成, 在单物种记录方面的平均精度为0.791.Xie等(2022)在CLDNN (CNN-LSTM-DNN)模型中引入卷积注意力机制, 使其分类性能提高. ... What is the ground truth? Reliability of multi-annotator data for audio tagging 1 2021 ... 公民科学项目基本依赖鸟类爱好者等, 用户表现出更高的技能、更多的时间和设备投资以及更高的个人承诺(Randler, 2021).但是非专家标注者可能提供不正确或者不一致的标签.为了提升标签的质量, 扩大参与者范围, 众包任务组织者应该关注数据的质量控制、激励机制、任务分配、隐私保护等方面.质量控制的策略包括3种, 第一种是提升数据标签质量.Aydin等(2014)对在标注过程中表现好的众包工人的标注结果赋予较大的权重, 使得其对最终标签产生较大影响.Kulkarni等(2012)提出迭代完成标注任务, 即参与者在前一个参与者的标注工作的基础上进行改进.Yang等(2020)使用贝叶斯方法估计标注结果和真实标签的一致性, 了解人工标注员的标注准确率, 可以用于改进标注过程.为了汇总公民科学项目中具有不同背景和专业水平的非专家标注者的意见, Martín-Morató和Mesaros (2021)使用多标注者能力估计(multi-annotator competence estimation, MACE)根据具有不同专业知识背景和能力水平的非专家用户的注释来估计标签质量.传统聚合方法虽然减少了标签的错误率, 但是无法反映出某个标签有多大程度的不确定性.所以Wu等(2021)使用图神经网络从混乱的标签中推断出正确的标签, 同时保留标签的不确定性信息.Zhang等(2023)根据标注人员的特异性将参与者分为标注人员和检查人员, 标注人员对数据进行初步标注, 检查人员对标签进行审核和修正.分层众包的方式可以根据标签的不确定性动态调整标注和审核方法, 不断提高标签质量. ... 3 2024 ... Méndez Méndez等(2019)提出新的标注模型(图2), 包含前向循环(机器→众包参与者→专家)和后向循环(机器→专家→众包参与者).前向循环可提高标签的质量, 后向循环可促进用户学习以及提高用户参与度, 并且详细描述使用模型时的标注步骤(Méndez Méndez, 2024).双循环系统中, 前向循环机器学习将难以聚类的数据留给众包, 众包参与者通过多数投票机制提供标签, 如果同意率低于阈值,再由鸟类专家进行标注, 专家赋予标签后传递给模型学习.后向循环将聚类后的数据集提供给专家, 附上数据集统一标签, 专家给众包志愿者提供标注反馈, 提升参与者的专业知识, 如果志愿者的专业度提升, 可以减少时间成本和邀请专家的资金.众包参与者提供标签之后将带标签的数据集传递给模型, 继续模型训练.为了证实双循环标注模型的有效性, 研究人员将其应用于SONYC-UST数据集, 为该城市噪音数据集中的音频提供了标签(Cartwright et al, 2019). ...
虽然半自动标注方法综合了自动标注和人工标注的优点, 但其包含模型、专家和众包参与者3个模块, 标注项目组织者应该注意众包参与者信誉管理、标签质量管理、任务分配、激励机制等问题.目前的任务分配方法是组织者根据自己的需求在众包平台网络社区发布任务, 工作者根据自己的技能和兴趣爱好选择任务.如果众包标签的质量差, 不仅导致模型性能差而且增加专家的工作强度.为了控制质量和成本, 研究人员关注众包任务分配方法的研究, 特别是根据工人的偏好和特性选择标注者.Yuen等(2015)根据工人和任务之间的交互行为推断用户偏好, 实现任务的个性化推荐.汤小月等(2017)提出的基于支配分解的离散大多目标优化算法, 能够根据用户的质量需求快速找到最优解集.Awwad等(2017)基于工人的历史任务, 根据其在不同任务中的工作效率选择工人.刘勇等(2018)提出基于用户兴趣的传播模型, 该模型以高于贪心算法的效率推荐任务.Abdullah等(2020)提出基于贝叶斯网络的方法, 根据专业知识、工作量等属性为每项任务选择工人.Jiao等(2022)采用细粒度的批处理方法, 引入非平稳设置考虑动态变化, 有效完成任务分配问题.Rahman和Abdullah (2023)使用模糊推理系统, 基于多信任和信誉因素计算工人的可信度, 使用朴素贝叶斯进行情感分析, 识别潜在恶性工作者, 并且对于新注册的工人的冷启动问题, 使用系统中的最小信誉值初始化新工人的信誉度.虽然这些方法依据工人的爱好、专业知识、信誉度等推荐任务, 但是主要根据发布者的需求选择工人, 着重考虑了需求者的利益, 忽略了工人的利益.Zhao等(2024)设计了一种基于贪婪和均衡的联盟的任务分配方法, 最大化工人的整体回报.作为任务发布者, 在分配工作时需要综合考虑多方面的利益.首先, 要基于项目的质量要求和时间限制, 精心挑选合适的工人, 确保任务能够高效且精准地完成.其次, 对工人的利益给予充分考虑, 这样不仅能维护他们的权益, 还能激发他们的积极性, 进而提高工作效率和成果的质量.通过平衡这些因素, 可以构建一个互利共赢的工作环境, 促进项目的顺利进行. ... Machine- crowd-expert model for increasing user engagement and annotation quality 1 2019 ... Méndez Méndez等(2019)提出新的标注模型(图2), 包含前向循环(机器→众包参与者→专家)和后向循环(机器→专家→众包参与者).前向循环可提高标签的质量, 后向循环可促进用户学习以及提高用户参与度, 并且详细描述使用模型时的标注步骤(Méndez Méndez, 2024).双循环系统中, 前向循环机器学习将难以聚类的数据留给众包, 众包参与者通过多数投票机制提供标签, 如果同意率低于阈值,再由鸟类专家进行标注, 专家赋予标签后传递给模型学习.后向循环将聚类后的数据集提供给专家, 附上数据集统一标签, 专家给众包志愿者提供标注反馈, 提升参与者的专业知识, 如果志愿者的专业度提升, 可以减少时间成本和邀请专家的资金.众包参与者提供标签之后将带标签的数据集传递给模型, 继续模型训练.为了证实双循环标注模型的有效性, 研究人员将其应用于SONYC-UST数据集, 为该城市噪音数据集中的音频提供了标签(Cartwright et al, 2019). ... Sound event detection: A tutorial 1 2021 ... 在录制音频的过程中, 传感器持续运转, 有可能较长时间段内不会记录到任何鸟类叫声, 从而形成静默段.静默段不仅会占用存储空间, 还会降低模型的识别效果(Colonna et al, 2015).声音事件检测技术的目标是识别音频信号中发生的事件及其发生的时间(Mesaros et al, 2021).通过这项技术, 可以有效地筛选出包含鸟类叫声的音频段, 并丢弃不包含任何声音事件的静默段.带强标签的数据集中, 每个音频样本都标明了整个音频中存在的鸟类声音种类以及时频分布.为了标注强标签, 需要使用鸟声检测技术识别音频的有声段.在声学事件检测研究中, 由于研究人员使用的是不同的数据集和不同的指标, 因此难以进行模型识别性能的直接比较, 而DCASE竞赛专注于鸟声事件检测, 采用相同的数据集和指标, 可以进行模型性能的直接比较.附录3总结了2021-2023年DCASE获胜团队的模型和性能. ... Segmentation and characterization of acoustic event spectrograms using singular value decomposition 2 2019 ... 手动提取的人工特征主要有4种: 时域特征、频域特征、图像特征和时频特征.表3总结了常用的人工特征及其提取方法.常用的时域特征有短时过零率等(Marin-Cudraz et al, 2019), 频域特征有感知线性倒谱系数(Reynolds, 1994)等.单独的时域特征或者频域特征识别率低(Jin et al, 2023).研究人员使用声谱图提取特征, 比如图像频率统计(Bastas et al, 2012)、形状特征(Lee et al, 2013)等.时频特征是一种描述鸟鸣声时间和频率特征的方法, 提取时频特征的方法很多, 如离散小波变换(Sun et al, 2013)、小波包分解(Xie et al, 2016)、短时傅里叶变换(Mulimani & Koolagudi, 2019)、梅尔频率倒谱变换(Usman et al, 2020)等.为了提升识别效果, 可将多个时频特征进行融合(Zhang et al, 2021).鸟类交流中对于声音中的精细结构特别敏感, 但是手动提取的鸟声特征趋向于人类的理解, 可能忽略了鸟类声音的时序变化等重要特征(Dooling & Prior, 2017), 并且人工时频变换提取特征易造成信息损失, 使用卷积、长短期记忆深度神经网络(Sainath et al, 2015)、SincNet (Bravo Sanchez et al, 2021)等网络可以减少损失.一维卷积神经网络(Xie et al, 2021b)、自动编码器(Xie et al, 2020)、WaveNet (Van den Oord et al, 2016)等可以得到下游任务需要的特征, 与其他深度学习模型结合, 可实现更好的分类或者检测效果. ...
本文的其它图/表
|

{kind=link}