基于机器学习鸟声识别算法研究进展
申小虎, 朱翔宇, 史洪飞, 王传之
生物多样性
2023, 31 ( 11):
23272-.
DOI: 10.17520/biods.2023272
监测生态系统中鸟类多样性的状态和趋势是一项重大挑战, 需要广泛适用的基于机器学习的鸟鸣识别算法。为准确把握基于机器学习的鸟声识别方法的研究现状与发展趋势, 本文介绍了鸟鸣识别任务的基本概念, 并从模型结构设计角度对基于机器学习的鸟鸣识别算法进行概述。鉴于基于机器学习的鸟鸣识别技术的跨学科性质, 根据研究方向将算法分为: 概率模型(probabilistic model)、模板匹配(template matching)、时序分析(time series analysis)、迁移学习(transfer learning)、数据融合(data fusion)、集成学习(ensemble learning)、度量学习(metric learning)和无监督聚类(unsupervised clustering)的鸟鸣识别算法。本文回顾了这些方法在完成鸟声识别任务时的技术脉络, 以及这些算法的特点和局限性, 并比较了它们在鸟鸣识别方面的有效性。本文还讨论了常用的标准化鸟声开源数据集和评估指标。最后, 本文指出当前方法所面临的挑战和该领域潜在的未来研究方向。本综述旨在为从事鸟声识别研究的学者和开发人员提供一个全面的参考框架, 以便更好地理解现有技术和潜在发展趋势。
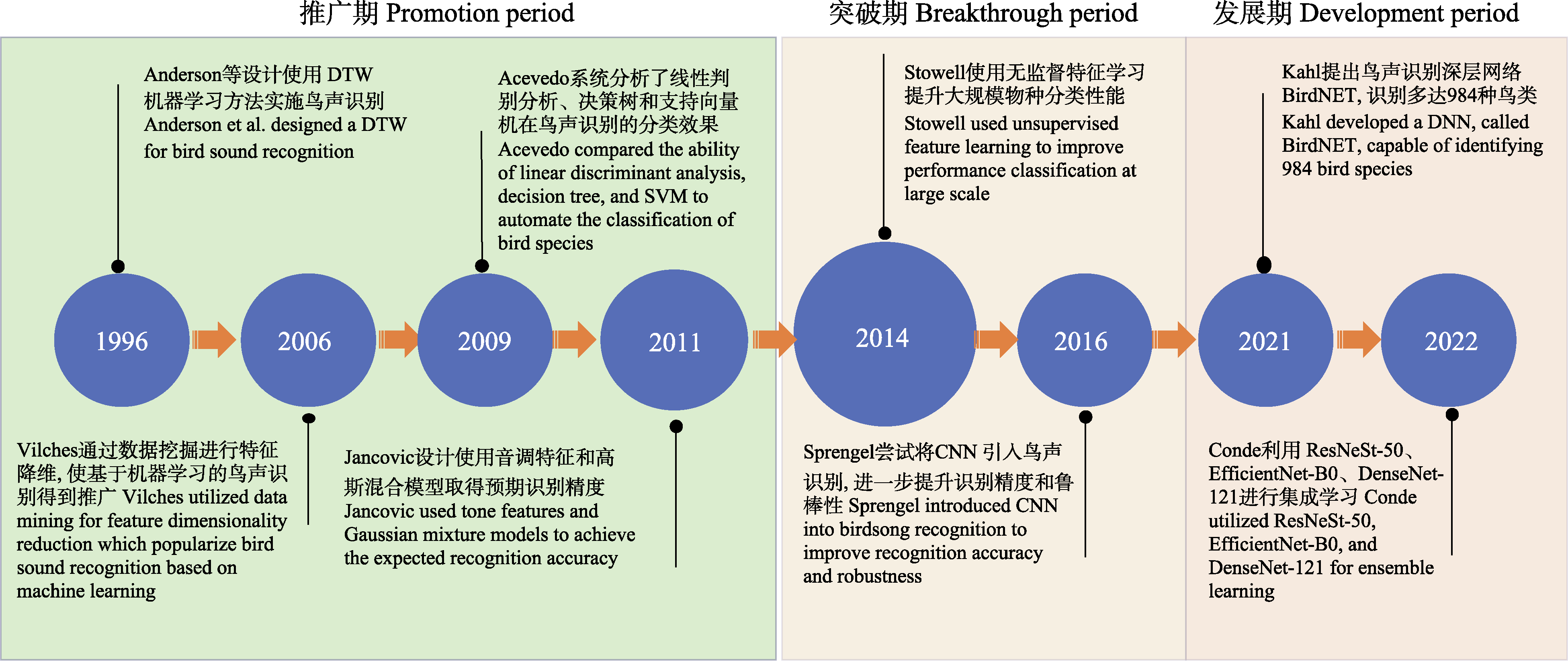
View image in article
图1
鸟声识别算法发展历程。DTW: 动态时间规整; SVM: 支持向量机; CNN: 卷积神经网络; DNN: 深度神经网络。
正文中引用本图/表的段落
基于机器学习(machine learning)的鸟声识别技术在生态监测中至关重要, 其通过自动识别和分类鸟声, 能够高效地追踪生物多样性的现状与变化趋势, 从而显著减少了对人类专家的依赖, 提高了处理效率。此外, 机器学习方法还可解决诸多实际问题, 如噪声干扰、类别不平衡以及鸟类声音的多样性。国外基于机器学习的鸟声识别研究相对广泛且起步较早(Priyadarshani et al, 2018), 可以追溯到20世纪90年代(Anderson et al, 1996)。21世纪以来, 国内外科研人员一直致力于改进基于机器学习的鸟声识别技术, 并使其得到广泛推广。该技术的发展可以划分为3个主要阶段, 即推广期、突破期和发展期(图1)。在推广期, 研究者们围绕传统机器学习开展研究, 研究领域主要聚焦在如何设计有效的特征提取模型(Vilches et al, 2006; Briggs et al, 2009; Lakshminarayanan et al, 2010)与改进优化线性分类器(Acevedo et al, 2009), 如支持向量机(support vector machine, SVM)、决策树(decision tree, DT)、线性判别分析(linear discriminant analysis, LDA)。在突破期, 随着深度学习(deep learning, DL)的兴起, 尤其是卷积神经网络(convolutional neural networks, CNN)的引入(Sprengel et al, 2016; Chandu et al, 2020), 研究者得以利用这些模型进行更为准确的鸟声识别。作为端到端的一种学习方式, 深度学习框架可以自动完成特征工程的工作, 开发者只需要关注参数优化即可得到效果较好的模型。此外, 可以满足少量带标签样本、无法明确鸟类物种的无监督聚类(unsupervised clustering)学习也在这个阶段得到广泛研究(Stowell & Plumbley, 2014)。尽管如此, 技术发展仍然面临挑战。为满足复杂野外场景条件下的鸟类物种检测, 2021年起, 研究者们尝试将数据融合(data fusion)、集成学习(ensemble learning)等策略更好地引入到该领域(Conde et al, 2021), 期望在大规模物种识别上获得鲁棒性(robustness)更强的模型。为了追求更高的识别准确性, 研究者还设计出具有更多层的网络模型(Kahl et al, 2021), 这导致模型参数量显著增加, 但这些复杂的模型可能并不适用于资源受限的嵌入式设备。为应对这一问题, 研究者们开始采纳如参数量化(parameter quantification)和知识蒸馏(knowledge distillation)等网络压缩方法。
Kaewtip及其合作者于2015年的研究中, 首次提到了“高能显著区域” (high-energy prominent regions)这一术语, 并结合DTW和SVM, 成功地对鸟声片段进行了分割(Kaewtip et al, 2015)。不久后, 在2016年, Kaewtip等基于传统的DTW方法, 设计出了一种适合小样本训练数据的稳健的鸟声检测策略(Kaewtip et al, 2016)。这一策略的核心步骤是: 首先对时频图进行对齐处理, 然后利用高能显著时频区域来提取对抗噪声(anti-noise)的模板。在模型的训练阶段, 算法通过迭代的方式从训练数据中抽取出可信赖的信息, 并据此为每一种鸟声生成一个匹配模板。值得注意的是, 每一个模板都包括三大部分: 参考时频图、显著区域和1个帧加权函数。而在分类阶段, 给定的时频图会通过动态规划与每一种模板进行比对。另外, 孙斌等(2015)指出, 传统时频图的一大问题是其具有非稳态的特点。为了解决这一问题, 他们提出了一种自适应最优核时频分布(adaptive optimal kernel, AOK)时频图, 能够更好地表示在不同时频尺度下的能量分布。基于AOK时频图, 他们计算了灰度共生矩阵, 进而生成了特征模板, 这些模板随后被用于DTW模板匹配。这种方法在一定程度上提高了模板匹配的效率, 但计算灰度共生矩阵的过程却需要消耗大量的计算资源。 DTW还可以与其他手工特征进行融合, 以形成综合特征。例如, 徐淑正等(2018)基于时频纹理特征, 在研究中进一步加入了音节长度、MFCC、DTW等特征, 并采用多分类器的策略进行鸟声分类。
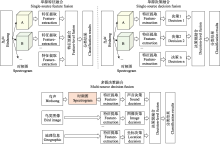
本文概述了基于机器学习的鸟声识别方法, 比较了当前先进识别方法之间的优劣, 并对这些方法的性能进行了分析.尽管目前基于深度学习的鸟声识别方法取得了一定的成绩, 但面向大规模数据样本时, 其准确性和鲁棒性还需要进一步提高, 推广应用仍面临以下挑战: ... 1 ... Adavanne等(2017)成功使用CRNN执行长时鸟声识别任务.Bai等(2018)也在DCASE2018挑战任务3中, 将降噪后的对数质谱图与MFCC谱图输入自定义激活函数的CRNN中进行鸟声事件检测, 达到预期的鸟声识别效果.CRNN结合了CNN和RNN的特点, 将CNN最后的卷积层改为RNN.在CRNN中, CNN和RNN分别承担特征提取和时间聚合的功能.针对RNN存在的梯度消失问题, 有研究(邢照亮等, 2021)将LSTM、GRU等时序模型与其他卷积网络进行比较, 发现CNN-LSTM模型更适合鸟声识别.此外, Carvalho和Gomes (2023)则较为全面地比较了CNN、RNN、LSTM、GRU、CNN-LSTM、CNN-GRU时序模型在91类物种上的表现, 同样得出CRNN及其变种可以更好地适用于鸟声识别的结论.此外, Qiao等(2020)使用Seq2Seq的深度学习方法, 用于无监督条件下的鸟声识别.该方法结合RNN与编码器- 解码器(encoder-decoder)范式来学习高层表示, 并选择使用SVM和多层感知器(multi-layer perceptron, MLP)进行决策输出鸟声类别. ... 1 2016 ... 此外, Morgan和Braasch (2022)为解决实际的长时鸟声检测问题, 探讨了开放数据集条件下的多种鸟声度量策略, 如预测得分阈值、基于距离的阈值和OpenMax (Bendale & Boult, 2016).该方案选择在ImageNet数据集上预训练过的VGG16模型, 生成平面分类模块(flat classifier block, FCB), 并采用了不同的FCB模块组合方式进行分类推断.具体而言, 该方法由1个粗粒度二值分类器(区分低频和高频声音)、2个中粒度二值分类器(区分脊椎动物、非脊椎动物与背景噪声)和4个多类细粒度分类器(物种分类)组成, 每个细粒度分类器均以上述鸟声度量策略方式建立. ... Cross-domain deep feature combination for bird species classification with audio-visual data 1 2019 ... 多源决策融合方法可从多模态数据信息中挖掘细节信息, 提升系统识别精度与鲁棒性.在鸟类识别研究领域, 鸟类图像信息与声音信息是最常用的两类模态信息.Bold等(2019)提出了多模态CNN鸟声识别体系结构, 并论证了图像和音频数据多模态下的后期融合方式.图7展示了该研究实验中采用的4类后期融合方式. ... Design and implementation of a robust acoustic recognition system for waterbird species using TMS320C6713 DSK 1 2017 ... 总的来说, 深度学习的鸟声识别可以省去复杂的特征工程, 并能够学习到鸟声与物种之间的复杂映射关系, 但这需要利用较大规模的鸟声样本进行训练.因此, 除上述学习策略外, 网络压缩在鸟声识别研究中也占据重要的位置.虽然相较于传统方法, 深度学习模型在鸟声检测上具有优势, 但是深度学习模型需要大量的计算资源和存储空间, 导致这些模型在嵌入式设备(Boulmaiz et al, 2017)上难以广泛应用.为克服这一限制, Zabidi等(2022)采用了一种基于二值化神经网络(binary neural networks, BNNs)的XNOR-Net用于鸟类声学事件检测.得益于XNOR-Net结构中的二进制权重和输入, 其内存需求压缩了32倍, 计算速度提高了58倍.同时, 对XNOR-Net的隐藏层进行了深入的性能分析和优化, 确保在最佳的超参数配置下仍能达到与基线算法相当的识别精度.预计随着被动声学监测(passive acoustic monitoring, PAM)在鸟声监测系统中得到广泛应用, 深度学习模型在受限计算能力下的进一步研究将持续增长.此外, 知识蒸馏、参数剪枝等深度学习模型的压缩和加速技术也会得到更多的关注和应用. ... 1 2009 ... 基于机器学习(machine learning)的鸟声识别技术在生态监测中至关重要, 其通过自动识别和分类鸟声, 能够高效地追踪生物多样性的现状与变化趋势, 从而显著减少了对人类专家的依赖, 提高了处理效率.此外, 机器学习方法还可解决诸多实际问题, 如噪声干扰、类别不平衡以及鸟类声音的多样性.国外基于机器学习的鸟声识别研究相对广泛且起步较早(Priyadarshani et al, 2018), 可以追溯到20世纪90年代(Anderson et al, 1996).21世纪以来, 国内外科研人员一直致力于改进基于机器学习的鸟声识别技术, 并使其得到广泛推广.该技术的发展可以划分为3个主要阶段, 即推广期、突破期和发展期(图1).在推广期, 研究者们围绕传统机器学习开展研究, 研究领域主要聚焦在如何设计有效的特征提取模型(Vilches et al, 2006; Briggs et al, 2009; Lakshminarayanan et al, 2010)与改进优化线性分类器(Acevedo et al, 2009), 如支持向量机(support vector machine, SVM)、决策树(decision tree, DT)、线性判别分析(linear discriminant analysis, LDA).在突破期, 随着深度学习(deep learning, DL)的兴起, 尤其是卷积神经网络(convolutional neural networks, CNN)的引入(Sprengel et al, 2016; Chandu et al, 2020), 研究者得以利用这些模型进行更为准确的鸟声识别.作为端到端的一种学习方式, 深度学习框架可以自动完成特征工程的工作, 开发者只需要关注参数优化即可得到效果较好的模型.此外, 可以满足少量带标签样本、无法明确鸟类物种的无监督聚类(unsupervised clustering)学习也在这个阶段得到广泛研究(Stowell & Plumbley, 2014).尽管如此, 技术发展仍然面临挑战.为满足复杂野外场景条件下的鸟类物种检测, 2021年起, 研究者们尝试将数据融合(data fusion)、集成学习(ensemble learning)等策略更好地引入到该领域(Conde et al, 2021), 期望在大规模物种识别上获得鲁棒性(robustness)更强的模型.为了追求更高的识别准确性, 研究者还设计出具有更多层的网络模型(Kahl et al, 2021), 这导致模型参数量显著增加, 但这些复杂的模型可能并不适用于资源受限的嵌入式设备.为应对这一问题, 研究者们开始采纳如参数量化(parameter quantification)和知识蒸馏(knowledge distillation)等网络压缩方法. ... High-performance large-scale image recognition without normalization 1 2021 ... 为了进一步推动鸟声识别技术的研究与标准数据集的建立, 国内外相关组织举办了多项鸟声识别挑战赛.例如, BirdCLEF专注于鸟声物种识别, DCASE专注于鸟声事件检测, 科大讯飞则自2021年起开始组织国内的鸟类识别挑战赛.其中, 历年BirdCLEF的任务是识别所提供的声景测试集中的所有鸟类, 均为多标签分类任务(含鸟类物种、录音位置、录音时间等).每个声景被分成5 s左右的片段, 参赛团队需对每个片段生成一个与概率分数相关的物种列表.近几年BirdCLEF的获胜团队所采用的模型和分数都被详细列在表3中.参赛者通常会尝试最新的网络结构作为预训练模型.在BirdCLEF2020中, 冠军团队所提出的算法没有使用预训练模型, 转而采用网络结构搜索(neural architecture search, NAS)进行建模, 可根据特定任务进行自适应调整网络架构.而在BirdCLEF2021中, 冠军团队采用了ResNet的变体——注意力分割网络(split-attention networks, ResNeSt) (Zhang C et al, 2021)作为鸟声识别模型.在BirdCLEF2022中, 冠、亚军团队分别采用了NFNet (normalizer-free ResNets) (Brock et al, 2021)和ReNeXt (Xie et al, 2017)模型.这些模型都是在其他鸟声识别研究中未被采用过的.在BirdCLEF2023中, 有参赛团队通过引入新的ConvNeXt网络(Liu et al, 2022)开展集成学习, 并获得了当年的竞赛冠军.该模型以Inception- V4为基础, 参考Transformer结构和训练策略, 采用了更加灵活的多尺度卷积设计.由此可见, 不断地引入新的网络模型和集成学习策略是取得竞赛胜利的关键, 而鸟声识别技术在未来也将持续地从实验室走向实际应用. ... Automatic classification of bird sounds: Using MFCC and Mel spectrogram features with deep learning 5 2023 ... 在深度学习框架下, 鸟声识别常被视作时频图(语图)的图像识别问题, 寻找适用的深度模型结构是鸟声识别的重要研究方向之一.除了CNN外, 循环神经网络(recurrent neural network, RNN) (Adavanne et al, 2017)、AlexNet (尹晨畅等, 2022)、长短时记忆网络(long short-term memory, LSTM) (Carvalho & Gomes, 2023)、ResNet (Lasseck, 2019)、密集连接卷积网络(densely connected convolutional networks, DenseNet) (Conde et al, 2021)等深度模型也被相继应用于鸟声的识别任务, 识别的准确性不断提高.接下来, 我们将深入探讨现有研究中的各种模型设计和学习策略, 以及它们在鸟声识别上的主要贡献. ...
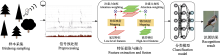
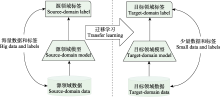
虽然某些文献使用了相同的鸟声数据库构建训练、验证和测试数据集, 但由于具体实验样本和选择的鸟种存在差异, 简单地通过实验结果进行性能对比是不合适的.然而, 可以明确的是, 随着识别的鸟类数量的增加, 识别精度呈现下降趋势(Lasseck, 2019).相较于在大量物种条件下采用数据增强技术的算法(Salamon et al, 2017; Kahl et al, 2021), 那些未采用数据增强技术的方法(LeBien et al, 2020; Carvalho & Gomes, 2023)在鸟声识别精度上仍存在很大的提升空间.如迁移学习可以增强模型的泛化能力, 使模型在鸟声识别任务上更好地适应未知数据.但当源领域与目标领域差异过大时, 可能会出现负迁移的情况, 这也解释了为何某些算法实验(Lasseck, 2019; LeBien et al, 2020)没有达到最佳性能.此外, 由于部分文献(Acconcjaioco & Ntalampiras, 2021; Morgan & Braasch, 2022)采用的是开放数据集, 因此选择评估标准为识别准确率(accuracy, Acc), 物种数是指带标签样本的物种数. ... 1 2015 ... 当然, 除了上述方法, 还有许多研究在提高分类器性能方面进行了尝试.例如, Joly等(2014)提出过一种基于实例的语义剪枝(semantic pruning)方法并应用于鸟类识别.具体方法包括使用高效的K最近邻(K-nearest neighbor, KNN)搜索方案在参考集中进行独立搜索, 接着使用滑动投票策略(sliding voting strategy)和最大池化(max-pooling)来确定每个检索到的记录的最佳匹配间隔, 并对它们进行排序, 最后通过一个简单的top-K分类器从检索记录的排序列表中导出一个强分类器.受细粒度(fine- grained)图像分类研究的启发, Joly等(2015)进一步提出共享最近邻匹配内核的鸟声识别方法, 其主要贡献是设计一种质量可控的高效近似最近邻搜索算法.此外, Mohanty等(2020)提出使用脉冲神经网络(spike neural network, SNN)进行特征分类, 与传统分类器相比, SNN具有更高的精度和更低的计算延迟. ... Deep learning-based bird sound recognition system with data pre-processing 1 2019 ... 鸟声识别问题中存在两个典型任务: 鸟声事件检测与鸟类物种分类(Nugroho et al, 2019).鸟声识别问题既可以采取单阶段模式(Narasimhan et al, 2017), 也可以采取两阶段模式(Vida?a-Vila et al, 2020), 即先检出鸟声事件, 再进行分类.整个流程大致分为4个阶段(Jung et al, 2019): 样本采集、预处理、特征参数提取、参数优化分类(图2). ... A robust automatic birdsong phrase classification: A template-based approach 1 2016 ... Kaewtip及其合作者于2015年的研究中, 首次提到了“高能显著区域” (high-energy prominent regions)这一术语, 并结合DTW和SVM, 成功地对鸟声片段进行了分割(Kaewtip et al, 2015).不久后, 在2016年, Kaewtip等基于传统的DTW方法, 设计出了一种适合小样本训练数据的稳健的鸟声检测策略(Kaewtip et al, 2016).这一策略的核心步骤是: 首先对时频图进行对齐处理, 然后利用高能显著时频区域来提取对抗噪声(anti-noise)的模板.在模型的训练阶段, 算法通过迭代的方式从训练数据中抽取出可信赖的信息, 并据此为每一种鸟声生成一个匹配模板.值得注意的是, 每一个模板都包括三大部分: 参考时频图、显著区域和1个帧加权函数.而在分类阶段, 给定的时频图会通过动态规划与每一种模板进行比对.另外, 孙斌等(2015)指出, 传统时频图的一大问题是其具有非稳态的特点.为了解决这一问题, 他们提出了一种自适应最优核时频分布(adaptive optimal kernel, AOK)时频图, 能够更好地表示在不同时频尺度下的能量分布.基于AOK时频图, 他们计算了灰度共生矩阵, 进而生成了特征模板, 这些模板随后被用于DTW模板匹配.这种方法在一定程度上提高了模板匹配的效率, 但计算灰度共生矩阵的过程却需要消耗大量的计算资源. DTW还可以与其他手工特征进行融合, 以形成综合特征.例如, 徐淑正等(2018)基于时频纹理特征, 在研究中进一步加入了音节长度、MFCC、DTW等特征, 并采用多分类器的策略进行鸟声分类. ... 2 2015 ... Kaewtip及其合作者于2015年的研究中, 首次提到了“高能显著区域” (high-energy prominent regions)这一术语, 并结合DTW和SVM, 成功地对鸟声片段进行了分割(Kaewtip et al, 2015).不久后, 在2016年, Kaewtip等基于传统的DTW方法, 设计出了一种适合小样本训练数据的稳健的鸟声检测策略(Kaewtip et al, 2016).这一策略的核心步骤是: 首先对时频图进行对齐处理, 然后利用高能显著时频区域来提取对抗噪声(anti-noise)的模板.在模型的训练阶段, 算法通过迭代的方式从训练数据中抽取出可信赖的信息, 并据此为每一种鸟声生成一个匹配模板.值得注意的是, 每一个模板都包括三大部分: 参考时频图、显著区域和1个帧加权函数.而在分类阶段, 给定的时频图会通过动态规划与每一种模板进行比对.另外, 孙斌等(2015)指出, 传统时频图的一大问题是其具有非稳态的特点.为了解决这一问题, 他们提出了一种自适应最优核时频分布(adaptive optimal kernel, AOK)时频图, 能够更好地表示在不同时频尺度下的能量分布.基于AOK时频图, 他们计算了灰度共生矩阵, 进而生成了特征模板, 这些模板随后被用于DTW模板匹配.这种方法在一定程度上提高了模板匹配的效率, 但计算灰度共生矩阵的过程却需要消耗大量的计算资源. DTW还可以与其他手工特征进行融合, 以形成综合特征.例如, 徐淑正等(2018)基于时频纹理特征, 在研究中进一步加入了音节长度、MFCC、DTW等特征, 并采用多分类器的策略进行鸟声分类. ...
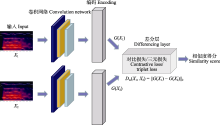
虽然某些文献使用了相同的鸟声数据库构建训练、验证和测试数据集, 但由于具体实验样本和选择的鸟种存在差异, 简单地通过实验结果进行性能对比是不合适的.然而, 可以明确的是, 随着识别的鸟类数量的增加, 识别精度呈现下降趋势(Lasseck, 2019).相较于在大量物种条件下采用数据增强技术的算法(Salamon et al, 2017; Kahl et al, 2021), 那些未采用数据增强技术的方法(LeBien et al, 2020; Carvalho & Gomes, 2023)在鸟声识别精度上仍存在很大的提升空间.如迁移学习可以增强模型的泛化能力, 使模型在鸟声识别任务上更好地适应未知数据.但当源领域与目标领域差异过大时, 可能会出现负迁移的情况, 这也解释了为何某些算法实验(Lasseck, 2019; LeBien et al, 2020)没有达到最佳性能.此外, 由于部分文献(Acconcjaioco & Ntalampiras, 2021; Morgan & Braasch, 2022)采用的是开放数据集, 因此选择评估标准为识别准确率(accuracy, Acc), 物种数是指带标签样本的物种数. ... Transound: Hyper-head attention transformer for birds sound recognition 1 2023 ... 多头注意力的优势在于: 一方面可以扩展模型获得关注长时鸟声时频图中不同位置的能力; 另一方面赋予注意力层多个表示子空间, 并将时频特征序列映射到不同的空间从而获得更强的长时依赖能力.近期, Transformer模型已被多项研究应用于鸟声检测分离(Zhang et al, 2022)、鸟声特征编码(Tang et al, 2023; 王基豪等, 2023)、端到端鸟声识别(Rauch et al, 2023), 但其在鸟声识别中的进一步优化设计仍是未来研究的焦点. ... Deep metric learning for bioacoustic classification: Overcoming training data scarcity using dynamic triplet loss 1 2019 ... 另一方面, 三元损失函数使用由锚定样本(anchor)、正样本和负样本构成的三元组, 目标是使锚定样本与正样本间的距离最小, 锚定样本与负样本间的距离最大.Thakur等(2019)提出了一个结合深度学习与传统度量学习的生物声学分类框架(deep metric learning, DML), 该框架利用了多尺度CNN框架和三元组损失函数, 在不同卷积核大小条件下提取特征, 并在线生成三元组, 实现在缺少带标签数据的情况下进行有效的深度度量学习.其采用的三元组损失函数如式(12)所示: ... A two-stage approach to automatically detect and classify woodpecker (Fam. Picidae) sounds 1 2020 ... 鸟声识别问题中存在两个典型任务: 鸟声事件检测与鸟类物种分类(Nugroho et al, 2019).鸟声识别问题既可以采取单阶段模式(Narasimhan et al, 2017), 也可以采取两阶段模式(Vida?a-Vila et al, 2020), 即先检出鸟声事件, 再进行分类.整个流程大致分为4个阶段(Jung et al, 2019): 样本采集、预处理、特征参数提取、参数优化分类(图2). ... 1 2006 ... 基于机器学习(machine learning)的鸟声识别技术在生态监测中至关重要, 其通过自动识别和分类鸟声, 能够高效地追踪生物多样性的现状与变化趋势, 从而显著减少了对人类专家的依赖, 提高了处理效率.此外, 机器学习方法还可解决诸多实际问题, 如噪声干扰、类别不平衡以及鸟类声音的多样性.国外基于机器学习的鸟声识别研究相对广泛且起步较早(Priyadarshani et al, 2018), 可以追溯到20世纪90年代(Anderson et al, 1996).21世纪以来, 国内外科研人员一直致力于改进基于机器学习的鸟声识别技术, 并使其得到广泛推广.该技术的发展可以划分为3个主要阶段, 即推广期、突破期和发展期(图1).在推广期, 研究者们围绕传统机器学习开展研究, 研究领域主要聚焦在如何设计有效的特征提取模型(Vilches et al, 2006; Briggs et al, 2009; Lakshminarayanan et al, 2010)与改进优化线性分类器(Acevedo et al, 2009), 如支持向量机(support vector machine, SVM)、决策树(decision tree, DT)、线性判别分析(linear discriminant analysis, LDA).在突破期, 随着深度学习(deep learning, DL)的兴起, 尤其是卷积神经网络(convolutional neural networks, CNN)的引入(Sprengel et al, 2016; Chandu et al, 2020), 研究者得以利用这些模型进行更为准确的鸟声识别.作为端到端的一种学习方式, 深度学习框架可以自动完成特征工程的工作, 开发者只需要关注参数优化即可得到效果较好的模型.此外, 可以满足少量带标签样本、无法明确鸟类物种的无监督聚类(unsupervised clustering)学习也在这个阶段得到广泛研究(Stowell & Plumbley, 2014).尽管如此, 技术发展仍然面临挑战.为满足复杂野外场景条件下的鸟类物种检测, 2021年起, 研究者们尝试将数据融合(data fusion)、集成学习(ensemble learning)等策略更好地引入到该领域(Conde et al, 2021), 期望在大规模物种识别上获得鲁棒性(robustness)更强的模型.为了追求更高的识别准确性, 研究者还设计出具有更多层的网络模型(Kahl et al, 2021), 这导致模型参数量显著增加, 但这些复杂的模型可能并不适用于资源受限的嵌入式设备.为应对这一问题, 研究者们开始采纳如参数量化(parameter quantification)和知识蒸馏(knowledge distillation)等网络压缩方法. ... 1 2019 ... 基于时间序列的识别法面临算法复杂度高的问题, 但新型时序模型, 如Gupta等(2021)引入的勒让德记忆单元(Legendre memory units, LMU) (Voelker et al, 2019), 为鸟声识别提供了新的思路.LMU的核心是Legendre多项式, 它是一组递归的正交多项式.相较于LSTM、GRU等传统时序模型, LMU的工作原理是将整个隐藏状态和输入(时序记忆)重复投影到多个Legendre多项式上.图4展示了经典时序模型的内部结构.可以看到, LSTM有3个门(遗忘门、输入门和输出门), 而GRU仅有两个门(更新门与重置门).GRU具有一个紧凑的门控机制可直接将隐藏状态h传给下一个单元, 而LSTM则用记忆单元把隐藏状态h包装起来, 其状态更新方程分别如式(1)、式(2)所示.LMU相当于没有门控机制的LSTM, 转而使用存储单元概念, 将一个n维状态向量(h)与一个d维内存向量(m)动态耦合, 投影更新方程如式(3)所示. ... 基于MFCC和双重GMM的鸟类识别方法 1 2014 ... 基于概率模型的识别法在传统的人声识别研究领域得到了广泛应用, 后来也被成功应用于鸟声识别(Jancovic & Kokuerl, 2011; 颜鑫和李应, 2013).其中, MFCC和LPCC这类声学特征, 因为与人耳听觉特性相契合, 并与频率具有非线性关系, 因而在多种声学特征描述中被采用.不少相关研究(王恩泽和何东健, 2014; Stastny et al, 2018)均使用这些基础特征, 并在其基础上进行进一步的特征设计与实验对比. ... 基于MFCC和双重GMM的鸟类识别方法 1 2014 ... 基于概率模型的识别法在传统的人声识别研究领域得到了广泛应用, 后来也被成功应用于鸟声识别(Jancovic & Kokuerl, 2011; 颜鑫和李应, 2013).其中, MFCC和LPCC这类声学特征, 因为与人耳听觉特性相契合, 并与频率具有非线性关系, 因而在多种声学特征描述中被采用.不少相关研究(王恩泽和何东健, 2014; Stastny et al, 2018)均使用这些基础特征, 并在其基础上进行进一步的特征设计与实验对比. ... 基于桥接Transformer的小样本优化鸟声识别网络 1 2023 ... 多头注意力的优势在于: 一方面可以扩展模型获得关注长时鸟声时频图中不同位置的能力; 另一方面赋予注意力层多个表示子空间, 并将时频特征序列映射到不同的空间从而获得更强的长时依赖能力.近期, Transformer模型已被多项研究应用于鸟声检测分离(Zhang et al, 2022)、鸟声特征编码(Tang et al, 2023; 王基豪等, 2023)、端到端鸟声识别(Rauch et al, 2023), 但其在鸟声识别中的进一步优化设计仍是未来研究的焦点. ... 基于桥接Transformer的小样本优化鸟声识别网络 1 2023 ... 多头注意力的优势在于: 一方面可以扩展模型获得关注长时鸟声时频图中不同位置的能力; 另一方面赋予注意力层多个表示子空间, 并将时频特征序列映射到不同的空间从而获得更强的长时依赖能力.近期, Transformer模型已被多项研究应用于鸟声检测分离(Zhang et al, 2022)、鸟声特征编码(Tang et al, 2023; 王基豪等, 2023)、端到端鸟声识别(Rauch et al, 2023), 但其在鸟声识别中的进一步优化设计仍是未来研究的焦点. ... 利用抗噪纹理特征的快速鸟鸣声识别 1 2015 ... 鸟声样本中每段的信息量并不相同, 因此, 选择合适的鸟声片段变得非常重要, 如图3所示.目前, 大量研究仍然采用手工方法进行音节分割(Chou & Ko, 2011), 这在基于机器学习的方法中是不实际的.于是, 有学者开始研究自动端点检测的方法.例如, 韩雪等(2023)采用双门限端点检测方法检测鸟声能量集中片段, 将鸟鸣信号中的短时能量(short-term energy)、短时平均幅度(short-term average amplitude)与时频图中的平均值(average value)、对比度(contrast)、熵(entropy)进行设计融合, 并采用协同粒子群参数优化算法后的SVM分类模型实现了鸟声分类.另外, 由于鸟鸣信号的非平稳性使其在时频图中具有丰富的物种信息特征, 因此, 也有研究尝试利用各种图像特征描述算子进行鸟声识别, 如灰度共生矩阵提取纹理特征(陈莎莎和李应, 2014; 魏静明和李应, 2015)、局部二进制模式(local binary pattern, LBP)、方向梯度直方图(histogram of oriented gradient, HOG) (杨春勇等, 2020)等.这些方法尽管避免了鸟声端点检测步骤, 但这些图像特征描述算子的计算量较大, 算法复杂性高. ... 利用抗噪纹理特征的快速鸟鸣声识别 1 2015 ... 鸟声样本中每段的信息量并不相同, 因此, 选择合适的鸟声片段变得非常重要, 如图3所示.目前, 大量研究仍然采用手工方法进行音节分割(Chou & Ko, 2011), 这在基于机器学习的方法中是不实际的.于是, 有学者开始研究自动端点检测的方法.例如, 韩雪等(2023)采用双门限端点检测方法检测鸟声能量集中片段, 将鸟鸣信号中的短时能量(short-term energy)、短时平均幅度(short-term average amplitude)与时频图中的平均值(average value)、对比度(contrast)、熵(entropy)进行设计融合, 并采用协同粒子群参数优化算法后的SVM分类模型实现了鸟声分类.另外, 由于鸟鸣信号的非平稳性使其在时频图中具有丰富的物种信息特征, 因此, 也有研究尝试利用各种图像特征描述算子进行鸟声识别, 如灰度共生矩阵提取纹理特征(陈莎莎和李应, 2014; 魏静明和李应, 2015)、局部二进制模式(local binary pattern, LBP)、方向梯度直方图(histogram of oriented gradient, HOG) (杨春勇等, 2020)等.这些方法尽管避免了鸟声端点检测步骤, 但这些图像特征描述算子的计算量较大, 算法复杂性高. ... 基于音节聚类分析的被动声学监测技术及其在鸟类监测中的应用 3 2023 ... Stowell和Plumbley (2014)的研究表明, 通过从数据中自动学习得到的特征表现通常优于手工设计的特征, 但构建大规模标注数据集往往需要大量的人力资源.因此, 为了缓解标注数据不足带来的问题, 部分研究者已经开始探索大规模无监督学习, 期待在不依赖显式特征提取的前提下提升分类的性能.除鸟声物种分类外, 某些文献(Petrusková et al, 2016; Marin-Cudraz et al, 2019)也运用无监督聚类方法对特定地区某些稀有鸟类的出现频次进行了研究, 但大多还是使用声学参数统计而非深度学习框架.鉴于深度学习方法在音节表征上展现出出色的性能, 吴科毅等(2023)提出了一种基于音节聚类与深度学习相结合的鸟声检测方法.该方法在特征提取阶段采纳了基于音高和频率平坦度的音节提取算法, 并综合使用了过零率(zero crossing rate)和能量(energy)辅助判定, 成功地解决了多物种鸟鸣叠加音节的特征提取问题.该方法采用非监督的变分编码器(variational auto-encoders, VAE)进行音节的无监督表征学习, 并使用狄利克雷混合模型(Dirichlet process mixture model, DPMM)引导模型确定聚类数量.尽管非监督学习方法在某种程度上缓解了弱标签和有限数据样本带来的挑战, 但从文献数量上看, 监督学习仍是鸟声物种识别的主流研究方向. ...
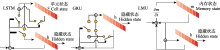
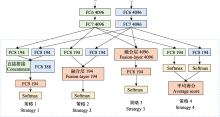
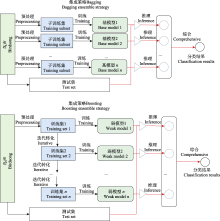
虽然某些文献使用了相同的鸟声数据库构建训练、验证和测试数据集, 但由于具体实验样本和选择的鸟种存在差异, 简单地通过实验结果进行性能对比是不合适的.然而, 可以明确的是, 随着识别的鸟类数量的增加, 识别精度呈现下降趋势(Lasseck, 2019).相较于在大量物种条件下采用数据增强技术的算法(Salamon et al, 2017; Kahl et al, 2021), 那些未采用数据增强技术的方法(LeBien et al, 2020; Carvalho & Gomes, 2023)在鸟声识别精度上仍存在很大的提升空间.如迁移学习可以增强模型的泛化能力, 使模型在鸟声识别任务上更好地适应未知数据.但当源领域与目标领域差异过大时, 可能会出现负迁移的情况, 这也解释了为何某些算法实验(Lasseck, 2019; LeBien et al, 2020)没有达到最佳性能.此外, 由于部分文献(Acconcjaioco & Ntalampiras, 2021; Morgan & Braasch, 2022)采用的是开放数据集, 因此选择评估标准为识别准确率(accuracy, Acc), 物种数是指带标签样本的物种数. ... 1 2017 ... 为了进一步推动鸟声识别技术的研究与标准数据集的建立, 国内外相关组织举办了多项鸟声识别挑战赛.例如, BirdCLEF专注于鸟声物种识别, DCASE专注于鸟声事件检测, 科大讯飞则自2021年起开始组织国内的鸟类识别挑战赛.其中, 历年BirdCLEF的任务是识别所提供的声景测试集中的所有鸟类, 均为多标签分类任务(含鸟类物种、录音位置、录音时间等).每个声景被分成5 s左右的片段, 参赛团队需对每个片段生成一个与概率分数相关的物种列表.近几年BirdCLEF的获胜团队所采用的模型和分数都被详细列在表3中.参赛者通常会尝试最新的网络结构作为预训练模型.在BirdCLEF2020中, 冠军团队所提出的算法没有使用预训练模型, 转而采用网络结构搜索(neural architecture search, NAS)进行建模, 可根据特定任务进行自适应调整网络架构.而在BirdCLEF2021中, 冠军团队采用了ResNet的变体——注意力分割网络(split-attention networks, ResNeSt) (Zhang C et al, 2021)作为鸟声识别模型.在BirdCLEF2022中, 冠、亚军团队分别采用了NFNet (normalizer-free ResNets) (Brock et al, 2021)和ReNeXt (Xie et al, 2017)模型.这些模型都是在其他鸟声识别研究中未被采用过的.在BirdCLEF2023中, 有参赛团队通过引入新的ConvNeXt网络(Liu et al, 2022)开展集成学习, 并获得了当年的竞赛冠军.该模型以Inception- V4为基础, 参考Transformer结构和训练策略, 采用了更加灵活的多尺度卷积设计.由此可见, 不断地引入新的网络模型和集成学习策略是取得竞赛胜利的关键, 而鸟声识别技术在未来也将持续地从实验室走向实际应用. ... 1 2021 ... 在近几年的跨学科研究中, 机器学习技术与鸟声识别的结合引起了广泛的关注.为了深入探究这一主题, 本研究集中分析了自2017年起在多个国际期刊(如Journal of Avian Biology、Ecological Informatics、Applied Acoustics)和国内期刊(如《生物多样性》《声学学报》《应用声学》《机器智能研究(英文版)》等)及顶级学术会议(如International Conference on Acoustics, Speech and Signal Processing、International Speech Communication Association、International Conference on Neural Information Processing)上发表的相关文章, 这些文章涵盖了鸟类学、声学技术和人工智能等领域.通过文献检索, 我们发现深度学习已成为鸟声识别研究的主导方法.然而, 一些传统的机器学习方法仍然适用于某些特定场景的鸟声识别(Mehyadin et al, 2021; Xie et al, 2021; 李大鹏等, 2022), 因此在实际应用中需结合数据条件与任务需求决定是否采用深度学习方法(Ghani & Hallerberg, 2021).基于上述考虑, 本文对近年来基于机器学习, 重点是基于深度学习的鸟声识别方法进行了总结与分析, 比较了不同方法之间的性能优劣, 以期为未来的鸟类识别算法研究提供帮助.截至目前, 国内外已有研究学者对鸟声识别技术开展过类似的综述工作.在国内综述文献中, 乔玉等(2020)针对中文文献进行了综述, 重点放在传统机器学习方法上, 对深度学习方法在鸟声识别中的应用介绍得较少, 忽略了深度学习策略对提升鸟声识别精度的帮助; 在国外综述文献中, 学者Priyadarshani等(2018)、Das等(2020)和Xie等(2023)均从信号处理的观点出发对鸟声物种识别的机器学习模型进行过归纳, 但重点放在鸟声预处理、特征提取方法和识别方法的总结上, 缺少对模型架构与学习策略的系统分析.随着近年来深度学习技术在鸟声识别中的进一步应用, 本文拟进一步完善鸟声识别算法的文献综述.本文的工作主要体现在以下3个方面: ... 面向鸟鸣声识别任务的深度学习技术 1 2023 ... 在单源特征融合的应用中, Xie等(2019)提出了一个简单朴素的单源特征融合方法.在预处理阶段, 该方法在Mel时频图的基础上进一步提取谐波分量(harmonic component)和瞬态响应分量(transient response component), 用于表征不同声学成分的鸟声时频.上述时频分量图谱分别输入卷积神经网络用于提取高层特征, 并在卷积池化后进行特征拼接融合.谢将剑等(2020)则提出一种基于自适应加权求和的特征级融合鸟声识别方法.该方法通过STFT、Mel倒谱、线性调频小波3类变换分别得到STFT语图、Mel语图和Chirplet语图, 再融合后输入softmax实现分类.上述单源特征融合的相关文献更多关注如何体现不同时频图对鸟声信号更加全面的表征与信息互补.与其他融合方法不同, 谢卓钒等(2023)的研究则更注重高层特征提取器的改造.该研究首先将梅尔谱特征与特征时间维度上的一阶、二阶特征相结合, 对鸟声信息进行表征并完成特征拼接融合.这种数据表征方式的主要创新在于通过DenseNet深层网络模型并引入自注意力机制提升了特征表达能力, 并通过结合交叉熵与中心损失函数来进一步优化网络训练. ... 面向鸟鸣声识别任务的深度学习技术 1 2023 ... 在单源特征融合的应用中, Xie等(2019)提出了一个简单朴素的单源特征融合方法.在预处理阶段, 该方法在Mel时频图的基础上进一步提取谐波分量(harmonic component)和瞬态响应分量(transient response component), 用于表征不同声学成分的鸟声时频.上述时频分量图谱分别输入卷积神经网络用于提取高层特征, 并在卷积池化后进行特征拼接融合.谢将剑等(2020)则提出一种基于自适应加权求和的特征级融合鸟声识别方法.该方法通过STFT、Mel倒谱、线性调频小波3类变换分别得到STFT语图、Mel语图和Chirplet语图, 再融合后输入softmax实现分类.上述单源特征融合的相关文献更多关注如何体现不同时频图对鸟声信号更加全面的表征与信息互补.与其他融合方法不同, 谢卓钒等(2023)的研究则更注重高层特征提取器的改造.该研究首先将梅尔谱特征与特征时间维度上的一阶、二阶特征相结合, 对鸟声信息进行表征并完成特征拼接融合.这种数据表征方式的主要创新在于通过DenseNet深层网络模型并引入自注意力机制提升了特征表达能力, 并通过结合交叉熵与中心损失函数来进一步优化网络训练. ... 基于C-LSTM的鸟鸣声识别方法 1 2021 ... Adavanne等(2017)成功使用CRNN执行长时鸟声识别任务.Bai等(2018)也在DCASE2018挑战任务3中, 将降噪后的对数质谱图与MFCC谱图输入自定义激活函数的CRNN中进行鸟声事件检测, 达到预期的鸟声识别效果.CRNN结合了CNN和RNN的特点, 将CNN最后的卷积层改为RNN.在CRNN中, CNN和RNN分别承担特征提取和时间聚合的功能.针对RNN存在的梯度消失问题, 有研究(邢照亮等, 2021)将LSTM、GRU等时序模型与其他卷积网络进行比较, 发现CNN-LSTM模型更适合鸟声识别.此外, Carvalho和Gomes (2023)则较为全面地比较了CNN、RNN、LSTM、GRU、CNN-LSTM、CNN-GRU时序模型在91类物种上的表现, 同样得出CRNN及其变种可以更好地适用于鸟声识别的结论.此外, Qiao等(2020)使用Seq2Seq的深度学习方法, 用于无监督条件下的鸟声识别.该方法结合RNN与编码器- 解码器(encoder-decoder)范式来学习高层表示, 并选择使用SVM和多层感知器(multi-layer perceptron, MLP)进行决策输出鸟声类别. ... 基于C-LSTM的鸟鸣声识别方法 1 2021 ... Adavanne等(2017)成功使用CRNN执行长时鸟声识别任务.Bai等(2018)也在DCASE2018挑战任务3中, 将降噪后的对数质谱图与MFCC谱图输入自定义激活函数的CRNN中进行鸟声事件检测, 达到预期的鸟声识别效果.CRNN结合了CNN和RNN的特点, 将CNN最后的卷积层改为RNN.在CRNN中, CNN和RNN分别承担特征提取和时间聚合的功能.针对RNN存在的梯度消失问题, 有研究(邢照亮等, 2021)将LSTM、GRU等时序模型与其他卷积网络进行比较, 发现CNN-LSTM模型更适合鸟声识别.此外, Carvalho和Gomes (2023)则较为全面地比较了CNN、RNN、LSTM、GRU、CNN-LSTM、CNN-GRU时序模型在91类物种上的表现, 同样得出CRNN及其变种可以更好地适用于鸟声识别的结论.此外, Qiao等(2020)使用Seq2Seq的深度学习方法, 用于无监督条件下的鸟声识别.该方法结合RNN与编码器- 解码器(encoder-decoder)范式来学习高层表示, 并选择使用SVM和多层感知器(multi-layer perceptron, MLP)进行决策输出鸟声类别. ... 集成学习方法: 研究综述 1 2018 ... 集成学习是一种混合建模技术, 能够结合不同模型的分类优势来优化决策.其中, Bagging和Boosting是两种经典的集成策略(徐继伟和杨云, 2018).图8展示了两者的差异: ... 集成学习方法: 研究综述 1 2018 ... 集成学习是一种混合建模技术, 能够结合不同模型的分类优势来优化决策.其中, Bagging和Boosting是两种经典的集成策略(徐继伟和杨云, 2018).图8展示了两者的差异: ... 基于MFCC和时频图等多种特征的综合鸟声识别分类器设计 1 2018 ... Kaewtip及其合作者于2015年的研究中, 首次提到了“高能显著区域” (high-energy prominent regions)这一术语, 并结合DTW和SVM, 成功地对鸟声片段进行了分割(Kaewtip et al, 2015).不久后, 在2016年, Kaewtip等基于传统的DTW方法, 设计出了一种适合小样本训练数据的稳健的鸟声检测策略(Kaewtip et al, 2016).这一策略的核心步骤是: 首先对时频图进行对齐处理, 然后利用高能显著时频区域来提取对抗噪声(anti-noise)的模板.在模型的训练阶段, 算法通过迭代的方式从训练数据中抽取出可信赖的信息, 并据此为每一种鸟声生成一个匹配模板.值得注意的是, 每一个模板都包括三大部分: 参考时频图、显著区域和1个帧加权函数.而在分类阶段, 给定的时频图会通过动态规划与每一种模板进行比对.另外, 孙斌等(2015)指出, 传统时频图的一大问题是其具有非稳态的特点.为了解决这一问题, 他们提出了一种自适应最优核时频分布(adaptive optimal kernel, AOK)时频图, 能够更好地表示在不同时频尺度下的能量分布.基于AOK时频图, 他们计算了灰度共生矩阵, 进而生成了特征模板, 这些模板随后被用于DTW模板匹配.这种方法在一定程度上提高了模板匹配的效率, 但计算灰度共生矩阵的过程却需要消耗大量的计算资源. DTW还可以与其他手工特征进行融合, 以形成综合特征.例如, 徐淑正等(2018)基于时频纹理特征, 在研究中进一步加入了音节长度、MFCC、DTW等特征, 并采用多分类器的策略进行鸟声分类. ... 基于MFCC和时频图等多种特征的综合鸟声识别分类器设计 1 2018 ... Kaewtip及其合作者于2015年的研究中, 首次提到了“高能显著区域” (high-energy prominent regions)这一术语, 并结合DTW和SVM, 成功地对鸟声片段进行了分割(Kaewtip et al, 2015).不久后, 在2016年, Kaewtip等基于传统的DTW方法, 设计出了一种适合小样本训练数据的稳健的鸟声检测策略(Kaewtip et al, 2016).这一策略的核心步骤是: 首先对时频图进行对齐处理, 然后利用高能显著时频区域来提取对抗噪声(anti-noise)的模板.在模型的训练阶段, 算法通过迭代的方式从训练数据中抽取出可信赖的信息, 并据此为每一种鸟声生成一个匹配模板.值得注意的是, 每一个模板都包括三大部分: 参考时频图、显著区域和1个帧加权函数.而在分类阶段, 给定的时频图会通过动态规划与每一种模板进行比对.另外, 孙斌等(2015)指出, 传统时频图的一大问题是其具有非稳态的特点.为了解决这一问题, 他们提出了一种自适应最优核时频分布(adaptive optimal kernel, AOK)时频图, 能够更好地表示在不同时频尺度下的能量分布.基于AOK时频图, 他们计算了灰度共生矩阵, 进而生成了特征模板, 这些模板随后被用于DTW模板匹配.这种方法在一定程度上提高了模板匹配的效率, 但计算灰度共生矩阵的过程却需要消耗大量的计算资源. DTW还可以与其他手工特征进行融合, 以形成综合特征.例如, 徐淑正等(2018)基于时频纹理特征, 在研究中进一步加入了音节长度、MFCC、DTW等特征, 并采用多分类器的策略进行鸟声分类. ... 利用抗噪幂归一化倒谱系数的鸟类声音识别 3 2013 ... 基于概率模型的识别法在传统的人声识别研究领域得到了广泛应用, 后来也被成功应用于鸟声识别(Jancovic & Kokuerl, 2011; 颜鑫和李应, 2013).其中, MFCC和LPCC这类声学特征, 因为与人耳听觉特性相契合, 并与频率具有非线性关系, 因而在多种声学特征描述中被采用.不少相关研究(王恩泽和何东健, 2014; Stastny et al, 2018)均使用这些基础特征, 并在其基础上进行进一步的特征设计与实验对比. ...
本文的其它图/表
|



{kind=link}